מייקרוסופט שינו את דעתם לגבי מצב ברירת המחדל של אקספלורר 8 לגבי תמיכה בתקנים.
הגישה הקודם עליה הם הכריזו אמרה בעצם שכל דף אינטרנט יכריז עבור איזה דפדפן וגרסאת דפדפן הוא נכתב, והדפדפן יצטרך להתאים את עצמו לשיטת הרינדור המתאימה לדף.
יש עם זה כמה בעיות – במקום שאתרי אינטרנט יכתבו כדי לעמוד בתקן מסויים, הם יכתבו כדי לעבוד היטב בדפדפן מסויים.
בעיה נוספת היא שכל דפדפן יצטרך להכיל קוד לתאימות עם כל הדפדפנים האחרים על כל גרסאותיהן, אם מפתחי הדפדפן רוצים שהוא יעבוד כראוי על כל אתר.
במילים אחרות, מחליפים פתרון שעלות הכתיבה שלו לינארית למספר התקנים הקיימים בפתרון שעלות הכתיבה שלו לינארית למכפלה של הדפדפנים בגרסאותיהם.
רק מייקרוסופט יכולה להרשות לעצמה דבר כזה, גם כי יש לה את כוח הפיתוח והQA הדרוש, גם כי הדפדפנים האחרים תמיד מנסים לעבוד לפי התקן, וגם כי היא יכולה להרשות לעצמה להתעלם מדפדפנים אחרים.
הדיווחים על הכוונות של מייקרוסופט עצבנו הרבה מאוד אנשים וחברות, שטענו בצדק שמייקרוסופט שוב מנצלת את הכוח שלה כדי לרמוס את התחרות ולקבור את האינטרנט תחת ערמת זבל חדשה, אחרי שסוף סוף המצב התחיל להשתפר.
נראה שמישהו במייקרוסופט הקשיב (ריי אוזי?) ושינה את המדיניות כך שכברירת מחדל IE8 יעבוד במצב תאימות לתקן (מייקרוסופט עדיין לא הוכיחו שהם מסוגלים לתמוך בתקן, אבל הכוונה פה מאוד חשובה).
השינוי התרחש בעקבות ההכרזה של מייקרוסופט מ21/2/2008 על שינוי במדיניות החברה לגבי תמיכה בתקנים ושקיפות גבוהה יותר של פרוטוקולים ופורמטים שהיו סגורים עד עכשיו.
השינוי במדיניות בא כדי לרצות את האיחוד האירופי, שנושף בעורפה של מייקרוסופט כבר שנים, ולוחץ עליה לשנות את דרכיה הנלוזות תוך גביית קנסות ענק.
מצחיק קצת לקרוא בפוסט הרלוונטי בIEBlog את הסיבה לשינוי:
We think that acting in accordance with principles is important, and IE8’s default is a demonstration of the interoperability principles in action. While we do not believe any current legal requirements would dictate which rendering mode a browser must use, this step clearly removes this question as a potential legal and regulatory issue. As stated above, we think it’s the better choice.
ובעברית:
אנחנו חושבים שעבודה לפי העקרונות (החדשים של מייקרוסופט) היא חשובה, ושינוי הגדרת ברירת המחדל של IE8 מדגים את המימוש של העקרונות האלו.
למרות שאנחנו לא מאמינים שדרישות משפטיות יכולות להכתיב באיזה מצב רינדור דפדפן צריך להשתמש, הצעד הזה מעלים את השאלה הזו כנושא משפטי או רגולטורי. כמו שכתבנו למעלה – אנחנו חושבים שזו בחירה טובה יותר.
או במילים אחרות:
אנחנו עושים את זה כתגובה על שינוי המדיניות, ואנחנו בכלל חושבים שזה רעיון טוב.
זה בכלל לא קשור ללחצים הרולטוריים והמשפטיים, אבל זה עוזר בחזית הזו.
אני בטוח שהם נתנו לעורכי הדין שלהם לאשר את המשפט הזה.
אז מה אתם אומרים?
מייקרוסופט שינתה את דרכיה?
(אני לא כותב את דעתי בכוונה כדי לא להשפיע על תוצאות הסקר):
אגב:
פוסט זה נכתב משדה התעופה בן גוריון.
מסתבר שיש פה אינטרנט חופשי, כך הכבוד להם.
מצד שני, שיתביישו על האתר שלהם (ממשלתי!), שדורש בחוצפה "דפדפן IE5.5 או חדש יותר".
בועז דולב, אתה קורא את זה?
גוגל אנטיליטיקס
דעתי על גוגל אנליטיקס ידועה, בקצרה:
גוגל אוספים מידע עלי ועליך כשאנחנו מסתובבים באינטרנט לתומינו, בכל מני אתרים שלא קשורים לגוגל.
איך? גוגל אנליטיקס, שמותקן בכל כך הרבה אתרים היום – מוסר לגוגל פרטים מפורטים על הגלישה שלך באתר כולל נתונים שמזהים אותך באתר.
סביר מאוד שגוגל יכולים להצליב את הזהות שלך באתר עם הזהות הגוגלית שלך (במילים אחרות – אם יש לך חשבון בגוגל, הם יכולים לדעת שאתה נכנסת לאתר מסויים שמשתמש בגוגל אנליטקס).
אני לא יודע אם גוגל באמת עושים את זה, אבל לדעתי גם אם לא – זה רק עניין של זמן עד שהם יתחילו כי זה יאפשר להם לפרסם בהתאם להיסטורית הגלישה שלך, מה שיכול להגדיל משמעותית את הרווחים שלהם.
עכשיו, לעניין.
מה דעתכם על תוסף פיירפוקס – נניח בשם גוגל אנטיליטיקס (שימו לב למשחק המילים המתוחכם), שיזהיר בצורה לא פולשנית (למשל איקון של מרגל בפינה העליונה של הדף) ברגע שאתם נכנסים לאתר שמריץ את גוגל אנליטיקס, ויאפשר גם לחסום בצורה גורפת את הדיווח של הדפדפן שלכם לגוגל?
פיירפוקס 3 בטא 3
הבטא השלישית של פיירפוקס 3 יצאה, ורשימת השיפורים די יפה.
אבל השיפור הכי משמעותי מבחינתי הוא בביצועים, הדפדפן טס ועד עכשיו לא נראה שהוא מתנפח ודולף כמו פיירפוקס 2.
אל תצפו שכל הפלאגינים יעבדו, אבל זה רק עניין של זמן.
שיפורים ששוה לשים אליהם לב הוא מנהל הסימניות החדש, שמאפשר לתייג סימניות, ומנהל רשימה אוטומטית של האתרים בהם אתם מבקרים הכי הרבה.
עוד שיפור יפה הוא כשמגדילים את הזום – תמונות גדלות עם הטקסט, מה ששומר על התסדיר של הדף.
מוזילה-לינקס פרסם סקירה מקיפה של השיפורים.
ומי שרוצה לשחק קצת עם פיירפוקס 3, אבל בלי לקלקל או להסיר את פיירפוקס 2?
אה, זה קל, אחרי שמוצאים הוראות באינטרנט :).
יוצרים פרופיל חדש עם הפיירפוקס החדש ככה:
[code]
/path/to/firefox -profilemanager -no-remote
[/code]
נניח שנקרא לו beta3test
ואחר כך כדי להפעיל את הפיירפוקס החדש מריצים את:
[code]
/path/to/firefox3 -P beta3test -no-remote &
[/code]
בצורה כזו, שני השועלים לא ידרכו אחד לשני על הזנב ויוכלו לרוץ במקביל בשדות האינטרנט הנצחיים.
יוניקוד ודגים אחרים
הערה: יש סקר בסוף.
סקירה היסטורית
בראשית היה ASCII (האמת היא שהיו קידודים לפני ASCII אבל הם לא מעניינים אותנו).
אסקי נועד בעיקר לתווים באנגלית, הערך של 'A' הוא 65, הערך של רווח הוא 32 וכן הלאה. ASCII הוא קידוד 7 ביטים, מה שאומר שהוא משתמש ב128 אפשרויות מתוך 256 האפשרויות שנכנסות בbyte.
הבעיה עם אסקי היא שהוא לא כולל תווים של שפות אחרות – קירילית ועברית למשל.
Code page
הפתרון המתבקש הוא להשתמש בערכים 128-255 כדי לייצג את האותיות החסרות.
הבעיה היא שהרבה אנשים חשבו על הפתרון הזה בו זמנית, ומטבע הדברים היו הרבה טבלאות כאלו, לפעמים אפילו כמה בתוך אותה מדינה.
לא נחמד, כי מסמך שנכתב תוך שימוש בטבלא אחת לא הוצג כמו שצריך למי שהשתמש בטבלא אחרת.
בשלב מסויים הוגדרו סטנדרטים על ידי ארגון התקינה האמריקאי (ANSI) , שנקראו Code pages, מה שעזר למנוע הווצרות של טבלאות מיותרות חדשות.
הבעיה העיקרית עם הפתרון הזה הוא שאי אפשר לערבב שפות שמשתמשות בקודים שונים.
בנוסף, הוא נותן פתרון רק לשפות בעלות פחות מ128 אותיות.
באסיה הוגדר תקן בשם DBCS – Double byte character set, שנועד לתת פתרון לשפות האסיאתיות.
התקן הזה השתמש בקידוד באורך משתנה: חלק מהתווים היו באורך בייט אחד וחלק באורך שני בייטים, ובאופן כללי היה מבלבל למדי.
UNICODE
יוניקוד הוא שם הקוד לטבלא גדולה מאוד שמתאימה מספר לכל אות ידועה (וגם כמה משפות מומצאות כמו קלינגונית), מכיוון שיש טבלא אחת לכל השפות – אין בעיה לערבב בין שפות שונות.
מיתוס נפוץ הוא שניתן לייצג כל אות ביוניקוד בעזרת מספר בין 16 סיביות (או במילים אחרות, שיש פחות מ65536 אותיות ביוניקוד).
זה לא נכון, ולמעשה יש ביוניקוד גרסא 4.0 קרוב ל240,000 סימנים, מה שאומר שצריך לפחות 3 בתים כדי למספר את כל התווים ביוניקוד.
מחרוזת ביוניקוד היא בסך הכל סדרה של מספרים, כאשר כל מספר הוא המיקום של אות מסויימת בטבלא.
מקובל לסמן תו יוניקוד בסימן כמו U+0041, כאשר U+ אומר שזה יוניקוד והמספר שאחריו הוא קוד האות בבסיס הקסדצימלי.
לא במקרה, 128 התווים הראשונים ביוניקוד הם בדיוק אותם 128 התוים הראשונים באסקי וברוב קידודי הCode page.
המחרוזת hello ביוניקוד תכתב ככה:
U+0048 U+0065 U+006C U+006C U+006F
אם נשמור את זה, נקבל:
[code]
00 48 00 65 00 6C 00 6C 00 6F
[/code]
או
[code]
48 00 65 00 6C 00 6C 00 6F 00
[/code]
תלוי בשיטת בה אנחנו מקודדים ספרות בזכרון המחשב (Little endian או Big endian).
כדי להבחין בין שתי השיטות ישנה תוספת של התווים FE FF בתחילת מחרוזת יוניקוד (שתראה ככה או הפוך, לפי הEndianness של המכונה).
הסימון הזה נקרא Unicode Byte Order Mark, או בקיצור BOM – והוא גורם ללא מעט צרות לדפדפנים שכתובים רע.
UTF-8
באו האמריקאים ושאלו, מה אנחנו צריכים את האפסים האלו באמצע המחרוזת? הרי המחרוזת תופסת פי שתיים, והם גם מבלבלים תוכנות שמתייחסות ל0 בתור סימון לסוף המחרוזת (מקובל בC וC++).
וככה נולד UTF-8.
UTF-8 הוא שיטה לקידוד יוניקוד בקידוד בעל אורך משתנה.
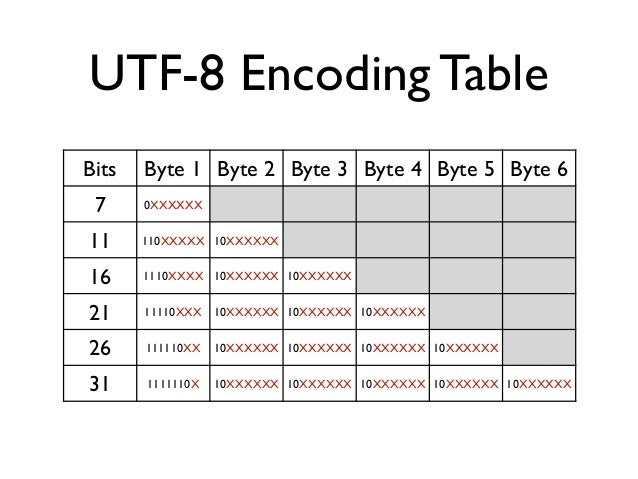
כשקוראים UTF-8, מסתכלים על התו הראשון ולפי הביטים הראשונים אפשר לדעת בדיוק על כמה בתים האות הבאה יושבת.
UTF-8 הפך לסטנדרט המקובל ביותר לקידוד מחרוזות יוניקוד.
PHP ויוניקוד
PHP התמיכה של PHP 4 ו5 ביוניקוד חלקית ביותר.
מחרוזות בPHP הן בעצם סדרה של בייטים ולא יותר ולמרות שתמיד אפשר להשתמש במחרוזת PHP כדי לשמור מחרוזות בקידודים שונים – רק במקרה שהPHP קומפל עם תמיכה בmb_string יהיו לנו פונקציות מיוחדות לטיפול במחרוזות מרובות בתים.
פתרון נוסף הוא להשתמש בספריה iconv, שמוסיפה לPHP יכולות המרה של קידודים, אבל היא לא מגיעה כברירת מחדל עם PHP ומי שרוצה תוכנה שתוכל לרוץ בקלות בכל מחשב ימנע ממנה.
בPHP 6 שמתבשל לאיטו צפויה תמיכה ביוניקוד, UTF-8 וכל זה, אבל זה עדיין לא שוחרר, ואם לשפוט לפי הקצב שלוקח לשוק לאמץ את PHP5 – אז PHP6 לא יהיה רלוונטי בשנים הקרובות למי שרוצה לשחרר תוכנה שתרוץ בכל מחשב.
מכיוון שהפונקציות הסטנדרטיות בPHP תומכות בעצם רק בקידוד שבו כל אות תופסת בייט אחד, הן יכולות ליצור בעיות מעניינות.
אם תקבלו מחרוזת שמקודדת בUTF-8, נניח "שלום", ותציגו אותה בדפדפן האורך שלה יהיה 4 אותיות. אם תשתמשו בפונקצית הPHP לחישוב אורך של מחרוזות, תקבלו שהאורך שלה הוא 8 תווים, כי כל אות מקודדת בשני בתים.
אם תנסו את אותו דבר על המחרוזת המעורבת "שלום SHALOM", תקבלו שהאורך הוא 8 + 1 + 6 = 15.
לעומת זאת, אם תשתמשו בmb_strlen תקבלו את האורך הנכון.
בעיה נוספת היא בעיה של חיתוך מחרוזות UTF-8.
אם נשתמש בפונקציה wordwrap לחיתוך מחרוזות UTF8, היא עלולה לחתוך אות בין שני הבתים שלה, ובעצם להעלים אותה. לא נעים.
הפתרון שלי היה לכתוב גרסא של wordwrap שעובדת על מחרוזות UTF-8.
אפשר להבין למה מפתחי PHP מתבלבלים כשהם מתעסקים עם מחרוזות בUTF-8.
המרות וקיבועים
למרות שרוב אתרי האינטרנט בימינו השכילו לעבור לUTF-8 לקידוד של מחרוזות, עדיין יש אתרים מסויימים שמשתמשים בקידודים מבוססי Code page. למשל – מנוע החיפוש של Walla מקודד לפעמים את מילות החיפוש בכתובת בקידוד עברית 1255 (עברית חלונות), ולפעמים בקידוד UTF-8. מאוד נחמד מצידם של המפתחים לפחות להעביר את הקידוד כחלק מהכתובת (e=hew לעברית 1255 וe=utf לutf8).
לא חסרות דוגמאות אחרות, בעיקר במנועי חיפוש מקומיים (yandex.ru, mail.ru שמשתמשים בקידוד קירילי 1251) ועוד.
מכיון שאני רוצה שמילות החיפוש יוצגו כמו שצריך בFireStats, צריך להמיר את הקידודים האלו לUTF-8.
הבעיה היא שכאמור – אין תמיכה מובטחת בiconv שמאפשר המרות כאלו, ולכן נאלצתי לכתוב בעצמי ספריית המרות קטנה מקידודי codepage כלשהם לקידוד UTF8. הספריה מסתמכת על טבלאות המרה שאפשר להשיג באתר הראשי של יוניקוד.
הרעיון של הספריה הוא להמיר באמצעות הטבלא את המחרוזת ליוניקוד, ואז לקודד אותה לUTF8.
וזו האגדה על אסקי יוניקוד וUTF-8.
קריאה נוספת
Joel on software במאמר מצויין על יוניקוד
מצגת על השרדות עם UTF-8
שאלות נפוצות על יוניקוד וUTF-8 בלינוקס ויוניקס
Unicode Introduction and Resources
עוד תקלת רשת מוזרה
בהמשך לפוסט האחרון על בעיות רשת מוזרות, הנה עוד אחת.
אפליקציית ג'אווה שכתבנו עובדת טוב לרוב האנשים, אבל משום מה "נתקעת" בהתחברות לחלק מהאנשים.
בבדיקה, נראה שהאפליקציה מתחברת לשרת, מקבלת תשובה ממנו, אבל לא קוראת את התוכן של התשובה.
בבדיקה מעמיקה יותר, רואים שהאפליקציה ניגשת לשדה הContent-Length של התשובה, ומקבלת משם 1-, מה שמרמז על זה שאין בתגובת הHTTP שדה של Content-Length.
בדיקה קטנה עם WireShark (לשעבר Ethereal) מראה את זה:
[code]
HTTP/1.1 200 OK
Date: Thu, 31 Jan 2008 13:21:24 GMT
Server: Microsoft-IIS/6.0
X-Powered-By: ASP.NET
X-AspNet-Version: 2.0.50727
Set-Cookie: ASP.NET_SessionId=j2hx2qvprzec3u55htsykh45; path=/; HttpOnly
Cache-Control: private
Content-Type: text/html
Content-Length: 20877
[/code]
(המשך התגובה נחתך מחוסר עניין).
אז נראה שהכל בסדר, יש Content-Length בתגובה.
ובכל זאת, אפליקציית הJava מקבלת 1-, ובדיבוג מעמיק אין רמז לContent-Length באובייקט שמייצג את תגובת הHTTP.
אז מה קורה פה?
הצעד הבא הוא לבדוק TCP נקי, בלי טובות של Java בפירסור התגובה.
תוכנית קטנה שמתחברת בTCP לשרת הHTTP, שולחת את הבקשה ומדפיסה את התוצאה מהשרת הפיקה את הפלט הזה:
[code]
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Date: Thu, 31 Jan 2008 13:21:24 GMT
Server: Microsoft-IIS/6.0
X-Powered-By: ASP.NET
X-AspNet-Version: 2.0.50727
Set-Cookie: ASP.NET_SessionId=j2hx2qvprzec3u55htsykh45; path=/; HttpOnly
Cache-Control: private
Content-Type: text/html
————–: —–
[/code]
יש פה כמה דברים שצריך לשים אליהם לב:
1. פתאום יש לנו בתשובה Transfer-Encoding: chunked.
2. מה זה איפה שקודם היה לנו Content-Length? ————–: —– ?? איזה וודו שחור פועל פה?
יש לציין שבזמן שאני מקבל את הנתונים האלו בתוכנית, אני מקבל נתונים זהים למה שראיתי קודם WireShark, כלומר – המחשב מקבל את הנתונים בצורה תקינה, אבל התוכנית מקבלת אותם אחרי טיפול.
כדי לנטרל אפשרות שJava התחלקה על השכל, ניסיתי (בעזרתו של חבר מהעבודה) להריץ תוכנית שעושה את אותו דבר בדיוק, רק שכתובה בC#.
לא במפתיע, התוצאה זהה: אין Content-Length, במקום זה יש שורת מינוסים.
מסקנה, Java לא אשמה הפעם.
אז מה נשאר?
מי משחק בתעבורת הרשת במחשב? אולי זה ווירוס, ואולי זה אנטי וירוס; בכל מקרה מדובר בתוכנה נאלחת.
לא במפתיע, האשם הוא הSymantec Client Firewall, שסורק בזמן אמת את תעבודת הHTTP, מחרבש אותה קלות, ומעביר את הזבל לתוכניות התמימות.
ברגע שנטרלתי את הסריקה שלו את פורט 80, הכל הסתדר.
יש לי משהו לומר למהנדסים של סימנטק:
אתם אינוולידים, מי נתן לכם את הזכות לשבש את התעבורה?
תסרקו, זה בסדר, אבל אין שום הצדקה שבעולם שהתוכניות שקוראות מהרשת יחשפו לשינויים שתרמתם.
אם הייתם עובדים אצלי הייתי משבש לכם את המשכורת.
אם הייתי כותב ווירוסים, הייתי משתמש במידע הזה בכיף כדי לזהות שהמחשב מריץ את הFirewall של סימנטק, שמשאיר עקבות כמו חזיר בחנות בורקסים.
012 וTorrentLeech
012 סמייל קווי זהב (או איך שלא קוראים להם היום), שנולדו מהרכישה של 012 על ידי אינטרנט זהב נחשדים בזיוף של תעבורה אינטרנט שנועדה לגרום להחרמה של משתמשי TorrentLeech.
בעבר היו לי לא מעט בעיות מהירות עם אינטרנט זהב שהסתיימו כשהתנתקתי מהם.
כבר בעבר חשדתי שאינטרנט זהב משתמשת בטכניקות מסויימות כדי לפגוע בקצב ההעלאה של משתמשים, ואם הטענות של מנהלי TorrentLeech נכונות, אז 012 סמייל קווי זהב (או איך שלא קוראים להם היום) עברו את הגבול הדק שבין ניהול משאבים על גבול הלגיטימי לזיוף נתונים כדי להפיק רווחים, פעולה פלילית ללא ספק.
יש דמיון עקרוני רב בין המקרה של Comcast, שזייפו חבילות RST שנועדו לגרום לצד השני לחשוב שהצד המחובר סגר את החיבור לבין מה שסמייל קווי זהב (או איך שלא קוראים להם היום) נחשדים בו.
הייתי אומר שהפתרון של Comcast יותר מתוחכם טכנולוגית ויותר קשה לזיהוי ושהפתרון של 012 (או איך בלה בלה) יותר גס טכנולוגית אבל יותר נבזי בהרבה.
הסיבה היא שהפתרון של 012 (בלה) נועד לגרום לשרתי TorrentLeech לחשוד שהמשתמש מנסה לגרום לאתר לחשוב שהוא העלה כמויות נתונים גדולות ולא סבירות במטרה לגרום להחרמתו מהאתר.
זו מתקפה מאוד ספציפית על משתמשי TorrentLeech, ואם זה אכן קרה, אני מצפה שכל משתמשי TorrentLeech שמחוברים דרך 012 (בלה) יתנתקו ויעברו לספק שלא חוסם/מגביל/מרמה/משקר/עובר על החוק (עדיין?) כמו בזק-בין-לאומי.
הערה:
הטענה של TorrentLeech לא הוכחה עדיין.
הנה ההודעה המקורית של TorrentLeech:
2008-01-24 – ISRAEL USERS
Unfortunately it seems, that a few Israeli ISPs, are intensionally altering the announces to our tracker of their clients, announcing to our tracker false stats (over 8.000.000 TB of upload and download) in order for these users to be probably banned (and save some bandwidth). We made a script to automatically detect this false announce, and reset the user's account (reset uploaded/downloaded). Although this is NOT a fix, only a temporary solution, we cannot do anything more from our part, since this is not a problem of our tracker. We know that reseting these accounts is not pleasant, but the other alternatives were to ban these accounts or to ban all the Israel Golden Lines ip block (which unfortunately seems very possible in the future, since our tracker gets hammered because of the problem above)
Seems most of the users having this problem use the ISP-> GOLDENLINES
חור אבטחה מובנה בUPNP
UPNP היא טכנולוגיה שנועדה לפשט את התהליך של הוספת שרתים ונקודות קצה לרשת. אחד השימושים הפופולריים של UPNP הוא לאפשר קידום פורטים אוטומטי.
נניח שיש לכם רשת מקומית קטנה מאחורי NAT (תצורה מאוד נפוצה בימינו, כמעט כל מחשב שמחובר לאינטרנט דרך נתב מהווה בעצם רשת מקומית כזו), ותוכנת שיתוף באחד המחשבים רוצה לאפשר התחברות אליה מבחוץ.
לפני UPNP, התוכנה לא תוכל לעשות את זה בעצמה, ומנהל המערכת (או המשתמש התמים שקנה את הנתב) יצטרך להגדיר את הנתב "ולפתוח פורטים", או ליתר דיוק – לקדם פורטים מסויימים אל המכונה הספציפית.
היום רוב הנתבים תומכים בUPNP, מה שמאפשר לתוכנת השיתוף למצוא את הנתב, לגלות שהוא תומך בקידום פורטים, ולבקש ממנו בדרכי נועם לקדם למחשב עליו היא רצה חבילות מידע שמגיעות לפורטים מסויימים.
מאוד נוח, הכל פשוט עובד.
הבעיה היא שUPNP לא כולל אימות (כי אחרת המשתמש היה צריך להגדיר שם משתמש וסיסמא בנתב לצרכים האלו, ולתת לתוכנת השיתוף את שם המשתמש והסיסמא, דבר לא נוח בעליל!) ולמעשה מאפשר לכל תוכנה שרצה של מחשב בתוך הרשת לבקש קידום פורטים בלי בקרה מיוחדת ובצורה שקופה ונסתרת מהמשתמש.
הבעיה מתחילה כהמשתמש מריץ תוכנה בלי להבין אפילו שזה מה שהוא עושה.
למשל, אתם גולשים לתומכם באינטרנט, בטוחים שהתוכנה היחידה שאתם מפעילים היא הדפדפן, אתם נכנסים לדף כלשהו שמציג אנימציית פלאש.
הופ, הרצתם תוכנה חיצונית.
לא הפלאש, אלא האנימציה עצמה.
בצורה דומה הפעלה של ישומון ג'אווה היא בעצם הפעלה של תוכנה חיצונית בתוך הרשת שלהם. במקרה של ג'אווה המצב עוד יחסית בסדר כי רק ישומונים חתומים יכולים להתחבר לשרתים אחרים מזה שהם ירדו ממנו (ישומים חתומים הם נדירים למדי כי כדי לחתום יש לרכוש חתימה מסמכות שורש כמו Verisign או Thawte, מה שעולה כמה מאות דולרים לשנה ויאפשר זיהוי של מקור הקוד).
לעניין, פלאש מאפשר התחברות לנתב ובקשה לקידום פורטים, בנוסף UPNP מאפשר בנתבים מסויימים לשנות את שרת הDNS של הנתב, מה שיכול לאפשר תכמון של המשתמש ברמות בלתי נתפסות.
מכיוון שכל נתב שנרכש בשנים האחרונות מתהדר בתמיכה בUPNP שמופעלת בדרך כלל כברירת מחדל, הבעיה די חמורה.
מומחי אבטחה מנסים לשכנע אנשים מזה שנים שנתב NAT הוא לא Firewall, אבל רוב האנשים לא מבחינים בהבדל. מבחינתם אם הם מאחורי נתב הם בטוחים והנתב הוא זה שיספוג את ההתקפות.
אז זהו, שלא.
למעשה, ווקטור ההתקפה הזה מנצל את האמון שאנחנו רוכשים למחשבים בתוך הרשת.
למשל, שרותים מקומים רבים מאפשרים התחברות מהמחשב המקומי בלבד (ובודקים שההתחברות מגיעה מהמחשב המקומי). הפעלת פלאש תמימה (ונסתרת) יכולה לעקוף את ההגנה הזו בקלילות (ואם פלאש עדיין לא תומך בקישוריות UDP/TCP, הוא בטח יתמוך בגרסאות הבאות).
מומלץ לנטרל את התמיכה בUPNP בנתב שלכם.
ההתקפה הודגמה בGnuCitizen.
Comcast, בדרך למטה?
בשעה טובה, התחילה חקירה נגד Comcast על ההתערבות הנבזית בתעבורת הרשת של המשתמשים שלה.
Comcast נתפסה מזייפת חבילות RST, טכניקה ערמומית ונכלולית להגביל תעבורת אינטרנט (דמיינו שאתם מתקשרים למישהו בטלפון, הוא עונה ואומר שהוא לא יכול לדבר כרגע, רק שבעצם זה לא הוא ענה, אלא ספק הטלפוניה שלהם שהגדיל ראש בכוונה להוריד מהעומס על רשת הטלפונים).
כתבתי כבר שכדאי מאוד שהשוק יראה לComcast שהטריקים האלו לא מקובלים ויכאיב לה איפה שכואב, אחת תתחיל מגפה של ספקיות שחוסמות תעבורת נתונים "לא לגיטימית" לאור יום.
חיפוש סרטים בגוגל
חיים טוב האמריקאים.
מי שרוצה למצוא סרט פשוט כותב בגוגל את שם העיר וCinema, למשל Renton cinema, ומקבל רשימת בתי קולנוע, ומה כל אחד מהם מציג היום.
מתי אצלנו?
איך להוציא RSS מאתר שלא תומך בRSS?
לפני כמה שבועות הפיד RSS של TorrentLeech (להלן TL), ספק הסדרות העיקרי שלי, התחיל להחזיר 404 (דף לא נמצא).
אין פה שום דבר חדש, הפיד הזה אף פעם לא היה יציב במיוחד, לכן חיכיתי בסבלנות כשבוע, ואז התלוננתי בערוץ הIRC שהלינק של הפיד לא עובד.
גורם "רשמי" מסר לי שהפיד לא יחזור כי השתמשו בו לרעה.
ניסיתי לברר את פשר השימוש הפוחז, ואפילו הצעתי את עזרתי במציאת פיתרון, אך לשוא:
הילדון זב החוטם מסר שלא משנה מה אני אגיד או אעשה, הפיד לא חוזר.
הסברתי לו בדרכי נועם שאם המידע זמין באתר, אין שום הבדל כי אפשר להפוך אותו לפיד, אבל זה לא עזר.
אז החלטתי לעשות בדיוק את זה, וכך נולדה תוכנה חדשה – TorrentLeech2RSS.
בגדול, הרעיון הוא כזה:
שרת מקומי דוגם את TL, נניח פעם בחצי שעה.
השרת נכנס לTL, מזדהה עם שם המשתמש והסיסמא של המשתמש בTL, מוריד את דף הHTML שמכיל את רשימת הטורנטים בכל אחת מהקטגוריות הנבחרות, מפענח את הדף, ומחלץ ממנו את השם, הלינק, המזהה והתאריך של כל טורנט, ושומר אותם בזכרון.
במקום להשתמש בכתובת הRSS של TL (שאינה עימנו עוד), המשתמש מכניס כתובת של TorrentLeech2RSS, שמכין דף RSS ומחזיר אותו למבקש.
TorrentLeech2RSS גם משכתב את הלינקים בתוך הRSS שיעברו דרכו, כדי שיוכל להוסיף פרטי הזדהות שיעברו לשרת של TL ברגע שהמשתמש מנסה להוריד טורנט (אחרת הTracker של TL לא משתף פעולה עם המשתמש).
בחרתי לכתוב את tl2rss בשפת ג'אווה.
הצעד הראשון, וכנראה הכי קשה בתהליך, הוא להכנס תכנותית לאתר, התהליך מורכב יחסית וכולל כמה שלבים.
כדי להבין מה אני אמור לשלוח ומתי, השתמשתי בWireShark, וניטרתי את התעבורה שנוצרת כשאני מבצע לוגין בעזרת הדפדפן.
שימו לב במיוחד לאפשרת של Follow TCP Stream, שמציגה שיחת HTTP שלמה בצורה ברורה.
ברגע שהקוד הצליח להזדהות מול השרת, לבקש דף שמתאים לקטגוריה רלוונטית זה קל. אבל מה עושים עם הדף?
הדפים של TorrentLeech הם דוגמא לאיך נראה קוד HTML מבולגן ולא תקני, ערבוביה של תגיות HTML שכוללות תוכן, עיצוב ועימוד.
בקיצור, לא משהו שכיף במיוחד לחפוש בתוכו אחרי מידע.
הגישה הנאווית לבעיות כאלו היא שימוש בביטוי רגולרי, אבל זה לא יעבוד טוב בכל המקרים (מה קורה למשל אם יש HTML בתוך התאור של הטורנט?).
בחרתי ללכת לגישה טיפה יותר חזקה, והיא פירוק מלא של הHTML למבנה נתונים בזכרון, וניתוח של אותו מבנה.
ספרית ג'אווה שמאפשרת parsing כזה לHTML היא htmlparser הוותיקה.
אבל גם אם htmlparser מחזירה לנו עץ אובייקטים נוח, איך מוציאים ממנו את מה שמעניין? הוא ענק וסבוך ויותר מכל מסובך.
למזלי מצאתי בונה פילטרים ויזואלי עם htmlparser. אפשר להריץ אותו עם Java web start:
[code]
javaws http://htmlparser.sourceforge.net/samples/filterbuilder.jnlp
[/code]
או פשוט להריץ את הקוד ישירות (org.htmlparser.parserapplications.filterbuilder.FilterBuilder). עורך הפילטרים מאפשר ליצור פילטרים מורכבים בהדרגתיות תוך בדיקה מתמדת של התוצאה על דף הHTML שאתם רוצים לבדוק.
אזהרה: הוא לא הכי ידידותי בעולם, לוקח זמן להתרגל אליו – אבל הוא עובד.
לדוגמא, נניח שאנחנו רוצים לחלץ את רשימת השחקנים מהסרט ביוולף בIMDB.
קודם נכניס בשורה התחתונה את הURL, אחר כך נלחץ על fetch page, ואז נקבל את הHTML כעץ בחלק הימני.
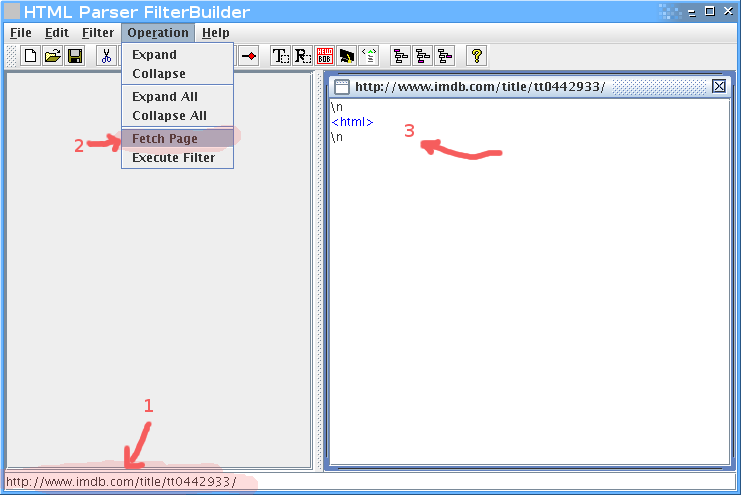
ברגע שיש לנו את הHTML, נתחיל לפלטר. חיפוש קצר אחרי שם של אחד השחקנים (Musician #2) מצא את הטבלא, ולמרבה הנוחות אפשר לראות שclass הCSS שלה הוא cast. זה מצויין, כי זה יאפשר לנו לדוג את הטבלא בקלות:
נוסיף פילטר של תכונות (attributes), נכניס בו את התכונה class עם הערך cast.
קליק ימני על הפילטר, execute filter, ונקבל חלון קטן בצד ימין עם התוצאות.
בינגו, יש לנו את הטבלה.
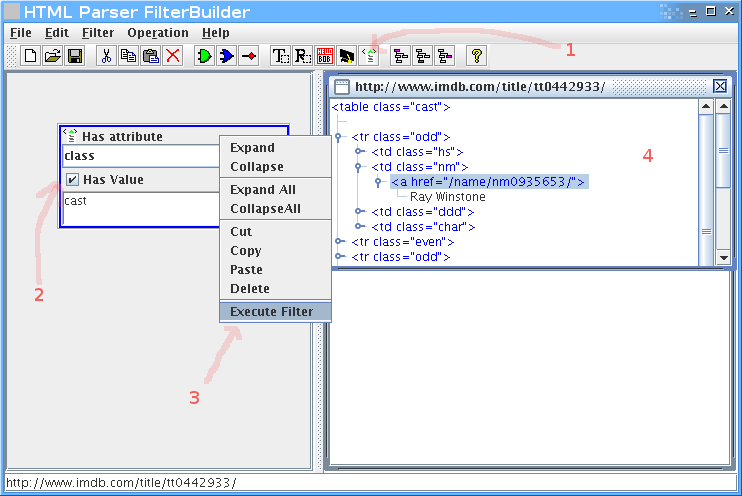
אבל אנחנו רוצים רק את רשימת השחקנים, אז צריך לעדן את הפילטר.
נוסיף שאנחנו רוצים רק טגים בשם TR, שיש להם הורה שהוא טבלא עם תכונה של class שערכו cast:
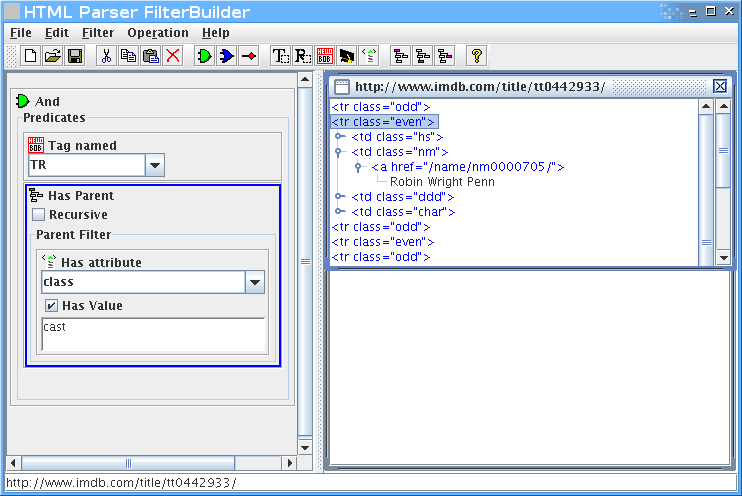
אפשר להמשיך, אבל הרעיון – אני מקווה – ברור.
ברגע שאנחנו מרוצים מהפילטר שיצרנו, אפשר לשמור אותו.
זה מה שיוצא (גרסא מקוצרת):
[code lang="java"]
// Generated by FilterBuilder. http://htmlparser.org
// [aced0005737200206f…….17374]
import org.htmlparser.*;
import org.htmlparser.filters.*;
import org.htmlparser.beans.*;
import org.htmlparser.util.*;
public class imdb
{
public static void main (String args[])
{
TagNameFilter filter0 = new TagNameFilter ();
filter0.setName ("TR");
HasAttributeFilter filter1 = new HasAttributeFilter ();
filter1.setAttributeName ("class");
filter1.setAttributeValue ("cast");
HasParentFilter filter2 = new HasParentFilter ();
filter2.setRecursive (false);
filter2.setParentFilter (filter1);
NodeFilter[] array0 = new NodeFilter[2];
array0[0] = filter0;
array0[1] = filter2;
AndFilter filter3 = new AndFilter ();
filter3.setPredicates (array0);
NodeFilter[] array1 = new NodeFilter[1];
array1[0] = filter3;
FilterBean bean = new FilterBean ();
bean.setFilters (array1);
if (0 != args.length)
{
bean.setURL (args[0]);
System.out.println (bean.getNodes ().toHtml ());
}
else
System.out.println ("Usage: java -classpath .:htmlparser.jar:htmllexer.jar imdb
}
}
[/code]
בראש הקובץ יש קידוד של הפילטר, מה שמאפשר לנו לטעון את הקובץ ולהמשיך לעבוד עליו מאותה נקודה.
כדי לקמפל את זה צריך כמובן את htmlfilter.jar בclasspath.
טוב, אז נניח שכתבנו פילטר מתאים, וגיבינו אותו בקצת קוד שמוציא את הנתונים לרשימה נוחה.
איך הופכים את זה לRSS?
בקלות, בעזרת ספרית ג'אווה בשם Rome.
השימוש ברומא פשוט מאוד, הנה דוגמא:
[code lang="java"]
public String getListRSS() throws FeedException
{
SyndFeed feed = new SyndFeedImpl();
feed.setFeedType("rss_2.0");
feed.setTitle("My RSS!");
feed.setLink("http://firefang.net/blog/768");
feed.setDescription("A feed for you!");
List entries = new ArrayList();
feed.setEntries(entries);
Vector v = new Vector();
v.add("item1");
v.add("item2");
v.add("item3");
for (int i = 0; i < v.size(); i++)
{
SyndEntry entry = new SyndEntryImpl();
entry.setTitle((String) v.elementAt(i));
entry.setLink("http:://imdb.com/");
entries.add(entry);
}
SyndFeedOutput output = new SyndFeedOutput();
return output.outputString(feed);
}
[/code]
שמפיקה את הRSS הזה:
[code lang="xml"]
[/code]
אז עכשיו שאנחנו יודעים לקחת דף HTML ולהוציא ממנו טקסט של RSS, נשאר רק לאפשר לקורא RSS רגילים לגשת אליו.
הדרך הטבעית תהיה להריץ שרת ווב קטן, שיגיש את קובץ הRSS למי שמבקש.
בחרתי להשתמש בJetty, שהוא שרת ווב קטן וגמיש בג'אווה, שמאפשר גם שילוב פשוט וקל בתוך אפליקציות אחרות.
לא להבהל מגודל ההורדה שלו, כדי להשתמש בו בתוך האפליקציה שלכם מספיק לקחת שלושה Jarים בגודל כולל של כ700K.
ככה משלבים את Jetty בתוך הישום שלכם, שימו לב כמה שזה פשוט.
[code lang="java"]
Handler handler=new AbstractHandler()
{
public void handle(String target, HttpServletRequest request, HttpServletResponse response, int dispatch)
throws IOException, ServletException
{
response.setContentType("text/html");
response.setStatus(HttpServletResponse.SC_OK);
response.getWriter().println("
Hello
");
((Request)request).setHandled(true);
}
}
Server server = new Server(8080);
server.setHandler(handler);
server.start();
[/code]
כדי לגשת אליו, נפתח את הדפדפן על http://localhost:8080 במקרה שלנו.
עכשיו רק נשאר לקשור את החוטים ביחד.
פתחתי בלוג קטן לפרוייקט, וחיש מהר החשבון שלי בTorrentLeech הושעה. כשביררתי מה הסיפור נאמר לי שהם חוששים שאני אגנוב למשתמשים סיסמאות.
הצעתי להם לבדוק את הקוד, ושעד אז אני אוריד את הלינק, וכך עשיתי, והחשבון שלי שוחזר.
בינתיים הם עדיין לא חזרו אלי, והסבלנות קצת פקעה.
מי שרוצה להוריד את הקוד יכול להוריד אותו מפה עם לקוח Subversion.
מי שרוצה להוריד את הבינארי מוזמן להוריד אותו מפה.
יש הוראות שימוש בתוך קובץ הREADME.
tl2rss משוחרר תחת רשיון GPL-3.0.