הערה: יש סקר בסוף.
סקירה היסטורית
בראשית היה ASCII (האמת היא שהיו קידודים לפני ASCII אבל הם לא מעניינים אותנו).
אסקי נועד בעיקר לתווים באנגלית, הערך של 'A' הוא 65, הערך של רווח הוא 32 וכן הלאה. ASCII הוא קידוד 7 ביטים, מה שאומר שהוא משתמש ב128 אפשרויות מתוך 256 האפשרויות שנכנסות בbyte.
הבעיה עם אסקי היא שהוא לא כולל תווים של שפות אחרות – קירילית ועברית למשל.
Code page
הפתרון המתבקש הוא להשתמש בערכים 128-255 כדי לייצג את האותיות החסרות.
הבעיה היא שהרבה אנשים חשבו על הפתרון הזה בו זמנית, ומטבע הדברים היו הרבה טבלאות כאלו, לפעמים אפילו כמה בתוך אותה מדינה.
לא נחמד, כי מסמך שנכתב תוך שימוש בטבלא אחת לא הוצג כמו שצריך למי שהשתמש בטבלא אחרת.
בשלב מסויים הוגדרו סטנדרטים על ידי ארגון התקינה האמריקאי (ANSI) , שנקראו Code pages, מה שעזר למנוע הווצרות של טבלאות מיותרות חדשות.
הבעיה העיקרית עם הפתרון הזה הוא שאי אפשר לערבב שפות שמשתמשות בקודים שונים.
בנוסף, הוא נותן פתרון רק לשפות בעלות פחות מ128 אותיות.
באסיה הוגדר תקן בשם DBCS – Double byte character set, שנועד לתת פתרון לשפות האסיאתיות.
התקן הזה השתמש בקידוד באורך משתנה: חלק מהתווים היו באורך בייט אחד וחלק באורך שני בייטים, ובאופן כללי היה מבלבל למדי.
UNICODE
יוניקוד הוא שם הקוד לטבלא גדולה מאוד שמתאימה מספר לכל אות ידועה (וגם כמה משפות מומצאות כמו קלינגונית), מכיוון שיש טבלא אחת לכל השפות – אין בעיה לערבב בין שפות שונות.
מיתוס נפוץ הוא שניתן לייצג כל אות ביוניקוד בעזרת מספר בין 16 סיביות (או במילים אחרות, שיש פחות מ65536 אותיות ביוניקוד).
זה לא נכון, ולמעשה יש ביוניקוד גרסא 4.0 קרוב ל240,000 סימנים, מה שאומר שצריך לפחות 3 בתים כדי למספר את כל התווים ביוניקוד.
מחרוזת ביוניקוד היא בסך הכל סדרה של מספרים, כאשר כל מספר הוא המיקום של אות מסויימת בטבלא.
מקובל לסמן תו יוניקוד בסימן כמו U+0041, כאשר U+ אומר שזה יוניקוד והמספר שאחריו הוא קוד האות בבסיס הקסדצימלי.
לא במקרה, 128 התווים הראשונים ביוניקוד הם בדיוק אותם 128 התוים הראשונים באסקי וברוב קידודי הCode page.
המחרוזת hello ביוניקוד תכתב ככה:
U+0048 U+0065 U+006C U+006C U+006F
אם נשמור את זה, נקבל:
[code]
00 48 00 65 00 6C 00 6C 00 6F
[/code]
או
[code]
48 00 65 00 6C 00 6C 00 6F 00
[/code]
תלוי בשיטת בה אנחנו מקודדים ספרות בזכרון המחשב (Little endian או Big endian).
כדי להבחין בין שתי השיטות ישנה תוספת של התווים FE FF בתחילת מחרוזת יוניקוד (שתראה ככה או הפוך, לפי הEndianness של המכונה).
הסימון הזה נקרא Unicode Byte Order Mark, או בקיצור BOM – והוא גורם ללא מעט צרות לדפדפנים שכתובים רע.
UTF-8
באו האמריקאים ושאלו, מה אנחנו צריכים את האפסים האלו באמצע המחרוזת? הרי המחרוזת תופסת פי שתיים, והם גם מבלבלים תוכנות שמתייחסות ל0 בתור סימון לסוף המחרוזת (מקובל בC וC++).
וככה נולד UTF-8.
UTF-8 הוא שיטה לקידוד יוניקוד בקידוד בעל אורך משתנה.
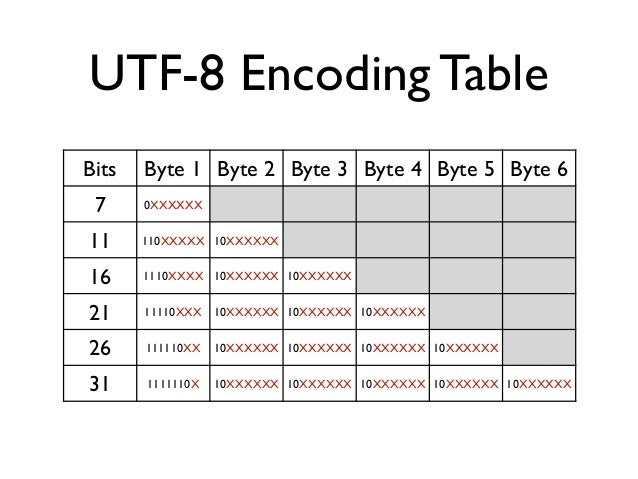
כשקוראים UTF-8, מסתכלים על התו הראשון ולפי הביטים הראשונים אפשר לדעת בדיוק על כמה בתים האות הבאה יושבת.
UTF-8 הפך לסטנדרט המקובל ביותר לקידוד מחרוזות יוניקוד.
PHP ויוניקוד
PHP התמיכה של PHP 4 ו5 ביוניקוד חלקית ביותר.
מחרוזות בPHP הן בעצם סדרה של בייטים ולא יותר ולמרות שתמיד אפשר להשתמש במחרוזת PHP כדי לשמור מחרוזות בקידודים שונים – רק במקרה שהPHP קומפל עם תמיכה בmb_string יהיו לנו פונקציות מיוחדות לטיפול במחרוזות מרובות בתים.
פתרון נוסף הוא להשתמש בספריה iconv, שמוסיפה לPHP יכולות המרה של קידודים, אבל היא לא מגיעה כברירת מחדל עם PHP ומי שרוצה תוכנה שתוכל לרוץ בקלות בכל מחשב ימנע ממנה.
בPHP 6 שמתבשל לאיטו צפויה תמיכה ביוניקוד, UTF-8 וכל זה, אבל זה עדיין לא שוחרר, ואם לשפוט לפי הקצב שלוקח לשוק לאמץ את PHP5 – אז PHP6 לא יהיה רלוונטי בשנים הקרובות למי שרוצה לשחרר תוכנה שתרוץ בכל מחשב.
מכיוון שהפונקציות הסטנדרטיות בPHP תומכות בעצם רק בקידוד שבו כל אות תופסת בייט אחד, הן יכולות ליצור בעיות מעניינות.
אם תקבלו מחרוזת שמקודדת בUTF-8, נניח "שלום", ותציגו אותה בדפדפן האורך שלה יהיה 4 אותיות. אם תשתמשו בפונקצית הPHP לחישוב אורך של מחרוזות, תקבלו שהאורך שלה הוא 8 תווים, כי כל אות מקודדת בשני בתים.
אם תנסו את אותו דבר על המחרוזת המעורבת "שלום SHALOM", תקבלו שהאורך הוא 8 + 1 + 6 = 15.
לעומת זאת, אם תשתמשו בmb_strlen תקבלו את האורך הנכון.
בעיה נוספת היא בעיה של חיתוך מחרוזות UTF-8.
אם נשתמש בפונקציה wordwrap לחיתוך מחרוזות UTF8, היא עלולה לחתוך אות בין שני הבתים שלה, ובעצם להעלים אותה. לא נעים.
הפתרון שלי היה לכתוב גרסא של wordwrap שעובדת על מחרוזות UTF-8.
אפשר להבין למה מפתחי PHP מתבלבלים כשהם מתעסקים עם מחרוזות בUTF-8.
המרות וקיבועים
למרות שרוב אתרי האינטרנט בימינו השכילו לעבור לUTF-8 לקידוד של מחרוזות, עדיין יש אתרים מסויימים שמשתמשים בקידודים מבוססי Code page. למשל – מנוע החיפוש של Walla מקודד לפעמים את מילות החיפוש בכתובת בקידוד עברית 1255 (עברית חלונות), ולפעמים בקידוד UTF-8. מאוד נחמד מצידם של המפתחים לפחות להעביר את הקידוד כחלק מהכתובת (e=hew לעברית 1255 וe=utf לutf8).
לא חסרות דוגמאות אחרות, בעיקר במנועי חיפוש מקומיים (yandex.ru, mail.ru שמשתמשים בקידוד קירילי 1251) ועוד.
מכיון שאני רוצה שמילות החיפוש יוצגו כמו שצריך בFireStats, צריך להמיר את הקידודים האלו לUTF-8.
הבעיה היא שכאמור – אין תמיכה מובטחת בiconv שמאפשר המרות כאלו, ולכן נאלצתי לכתוב בעצמי ספריית המרות קטנה מקידודי codepage כלשהם לקידוד UTF8. הספריה מסתמכת על טבלאות המרה שאפשר להשיג באתר הראשי של יוניקוד.
הרעיון של הספריה הוא להמיר באמצעות הטבלא את המחרוזת ליוניקוד, ואז לקודד אותה לUTF8.
וזו האגדה על אסקי יוניקוד וUTF-8.
קריאה נוספת
Joel on software במאמר מצויין על יוניקוד
מצגת על השרדות עם UTF-8
שאלות נפוצות על יוניקוד וUTF-8 בלינוקס ויוניקס
Unicode Introduction and Resources
אני חושב שיש שיפור בתמיכה של יוניקוד בגירסת PHP6
לפחות שמעתי… אולי אני טועה
אופס הבנת הנקרא D: אילו הייתי קורא ולא סורק את הטקסט… זה מה שקורה שבאגרגטור שלך יש 120 רססים ואני עובר על 315 פוסטים
לפי תוצאות הסקרים, הקוראים שלך חנונים. לא שזה מפתיע… 🙂
נראה מה יהיה כשיהיו יותר מ-5 הצבעות.
אגב, יש לי איזו יוזמה (שלא לומר יומרה) להעביר את כל ארכיוני אולטינט לרשת כ-UTF8 (אפילו שזה עדיין יהיה ויזואלי ולא לוגי), אולי אני אשתמש בספריה שלך…
העניין של 2 הבתים, היה בשביל לייצג את הל השפונת ה"נורמאליות" שלא דורשות יותר מ40 תווים. ככה שיפנית, סינית קוריאנית ושאר המשפחה מהמזרח לא נכנסו לטבלה, בעוד שכל שאר השפות תאורטית כן (למרות שעד עכשיו מכניסים עוד שפות לטבלה).
תו יכול להיות מ בית אחד עד ל4 בתים ב UTF-8.
יש לי עוד כמה הערות, אבל בסה"כ מאמר די יפה ומסכם. תמיך ככה.
לירון,
עברית ויזואלית? פיכס, אתה מהמאה הקודמת או משהו?! (צוחק).
כן, רעיון טוב.
רק שUTF-8 חייב להיות עברית לוגית, אחרת הוא יוצג הפוך.
מצד שני, אני חושב שלתקן את זה זה בסך הכל להפוך את המחרוזות בתהליך ההמרה.
ik_5,
"העניין" עם שני תווים נובע לדעתי מכך שיש שפות שתומכות ביוניקוד לכאורה שבחרו להשתמש בגודל תו של 2 בתים (ג'אווה, מישהו?!)
תו ביוניקוד 5.1 ניתן ליצוג בUTF בבית אחד עד ארבע, אבל הפורמט של UTF-8 תומך בקידוד של בית אחד עד שישה בתים לכל סימן.
אז UTF8 ימשיך איתנו אל תוך עידן החלל, בו נצטרך לקודד שפות של חייזרים.
ik5, ליתר דיוק:
תו ביוניקוד ניתן ליצוג בשלוש בתים, אבל צריך עד ארבע בתים בקידוד UTF-8.
למרות זאת, UTF-8 תומך בקידוד של עד תו של ארבע בתים שיתפוס שש בתים בUTF-8.
איך היית מסדר את הקידודים הבאים מבחינת 'מה עדיף להשתמש' ?
iso-8859-8
iso-8859-8-i
windows-1255
{אני יודע שתעדיף יוניקוד, גם אני. אבל בלת ברירה, איזה מהם הייתי מעדיף? איזה היית הכי שונא…}
יפה מאד, רק חבלה שהטבלה היחידה שנמצאה היא באחת התגובות, משום מה אצלך יש רק טבל"א"ות 😉
וכדי שאהיה מספיק ברור: כותבים טבלה ב-ה', תוכן המאמר איכותי ולכן מגיע לו גם להיות איחכותי מבחינה כתיבה/דקדוקית/תחבירית.
בהצלחה 🙂
ראיתי את המאמר עכשיו ועדיין לא קראתי, ולכן לא הצבעתי. אני רק רוצה לומר מראש שהדברים מאוד מעניינים ואני בטוח שאחרי שאקרא (מתי שהוא השבוע) זה יעשה לי סדר בדברים שאני מבין באופן חלקי בלבד.
תודה!
BUG, כמובן שעדיף UTF-8.
אבל, אם צריך להשתמש בקידוד לוקאלי, הייתי מעדיף
iso-8859-8-i (שהוא הלוקאלי הכי נכון)
אחרי iso-8859-8 (שהוא כמו חברו עם ה- i בסוף, אבל אחד מהם הוא visual והשני logical. מה זה אומר בעצם? יש לזה כל מיני משמעויות, אבל מה שחשוב לך לדעת, זה שפעם לא היה את ה- i, ואז כשהיינו מעתיקים טקסט מהאתר למעבד תמלילים או עורך טקסט, הוא היה מגיע הפוך. זה גם מה שיקרה אם תשתמש בו עכשיו).
הכי פחות מועדף הוא ה- windows-1255. למה? כי הוא מכיל תווים שקיימים רק בתוכנות מייקרוסופט, ומי שידפדף באתר שלך עם תוכנה שאינה מיקרוסופטית עשוי לראות תווים לא מזוהים.
מקווה שעזרתי,
the bartender
או, עכשיו יש לי למי לבכות כשאיתקל בבעיות קידוד.
Yisrael, לא חושב שזו ממש טעות.
שתי צורות הכתיבה מקובלות.
באג, תקרא את הפסקא הראשונה פה:
http://en.wikipedia.org/wiki/ISO_8859-8
לדעתי הבחירה היא בין 1255 לבין 8859-8-i.
אני חושב ש windows-1255 יותר נפוץ, אז אולי הוא עדיף.
Yisrael ועמרי, טבלא היא הצורה בכתיבה ארמית. טבלה היא הצורה בכתיבה עברית. במשך שנים רבות האקדמיה ללשון עברית קיבלה את שתי הצורות, וגרסה רק שיש להקפיד לכתוב טבלא וטבלאות, או טבלה וטבלות, ולא לערבב בין צורות יחיד ורבים של כתיב עברי וארמי.
לפני כמה שנים החליטה האקדמיה שלא לקבל יותר את התצורה הארמית, אך התצורה הארמית עדיין מאוד מקובלת בציבור, ואף נמצאת בשימושם של עורכים לשוניים ומגיהים.
לכן, כן, רשמית זו טעות, אך מעשית היא טעות מקובלת גם בין המומחים במקצוע.
או, אם לנסח אחרת, זו טעות דה-יורה, אבל נכון דה פקטו.
עמרי, לגבי תשובך ל- BUG, המאמר ששלחת רק מחזק את הטענה שלי.
iso-8859-8 עובר מן העולם לטובת ה- iso-8859-8-i בכדי להמנע מהצורך בכתיבה הפוכה.
ההתלבטות תהיה, אם כן, דווקא בין ה- i לבין ה- win-1255. אני הייתי פוסל את ה- win בגלל שהוא סט מייקרוסופטי, והוא ממפה מספר תווים בשונה מה- iso.
מפתיע אותי שגם אתה, משתמש ב- FF על debian, וגם bug, שמתשמש ב- FF על לינוקס, בכלל שוקלים את ה- 1255 כחלופה ל- ISO.
מקווה ששוב עזרתי,
the bartender
ברמן יקר, שים לב שצעתי לבאג לבחור בין 8859-8-i
רואה את ה "i" שם בסוף? שם החליט הדפדפן לדחוף אותה משום מה.
מבחינתי תקן הISO לא עדיף בכלום על התקן של MS, במקרה הזה זה נבלה וזה טרפה.
עדיף כבר את התקן שרוב האנשים משתמשים בו כדי שיהיו לו פחות צרות.
עמרי, לא ראיתי.
בהחלט, ה- 8 פס מן העולם.
ה- i עדיף, ולו במעט, כדי למנוע, לדוגמע, מעויינים שחורים עם סימני שאלה לבנים בתוכם ב- FF.
אבל כן, תמיד הכי טוב ללכת על ה- UTF-8 (אלא אם כן עובדים עם קבצים, במערכת שאין בה ריבוי שפות, ואז חבל על הגודל המיותר של הקבצים).
מה שכן, BUG, אם אתה עובד עם DB, תוודא שה- collation שאתה עובד איתו הוא UTF-8 אם אפשר מראש, כדי למנוע המרות בהמשך.
the bartender
@Yisrael:
עוד מעט עוד תגיד לי שכותבים דוגמה ולא דוגמא.
והתשובה: אתה לא תגיד לי באיזה שפה לדבר. אני אדבר ארמית כשאני רוצה לדבר ארמית. אין לי שום כוונה לפגוע, אבל יש לי התנגדות להסרה / החלפה של ה-א' הזו [כמו גם לעוד שינויים בשפת אליעזר בן יהודה לעומת עברית].
@the guinness bartender: @עומרי:
לא ביקשתי הסבר. אני לא מבין איך הגעתי למצב שאני מתפרש ככה. אני עובד לא מעט זמן עם קידודים, בסך הכל רציתי לשמוע חוות דעת של אנשים, זה הכל.
לגבי שקילת windows-1255, אז נכון שאני עובד עם לינוקס [ארצ' אם אתה רוצה לדעת]. אבל זה לא אומר שלא עבדתי בעבר בחברה לבניית אתרים שבנתה אתרים בצורה לא תקינה. זה היה סיוט. כל הקבצים שהיו מביעים לי היו ב windows-1255 והייתי צריך לעשות להם המרה של UTF-8 חוץ מבמקרים חריגים. ובגלל שכל-כך קשה לעבוד גם ככה עם הקודים שהיו שם, לא העברתי את הדברים במקרים החריגים ל iso-8859-i על מנת להימנע מנזקים.
באג, בוא נמנע מהתקפות פה.
מעניין מאוד! לא ידעתי על ההבדל בין unicode ל utf8, תמיד השתמשתי בmb וזה עבד סבבה…
אם כבר מדברים על יוניקוד אני מעונין לדעת איך אני יוצר שפה חדשה שמורכבת מכמה טבלאות למשל אני רוצה שבעברית יהיה יותר סימנים בלי שאני יצטרך להעביר שפה בסרגל שפות
בתודה מראש
צבי, אין לי מושג על איזה סרגל שפות אתה מדבר.