הערה: יש סקר בסוף.
סקירה היסטורית
בראשית היה ASCII (האמת היא שהיו קידודים לפני ASCII אבל הם לא מעניינים אותנו).
אסקי נועד בעיקר לתווים באנגלית, הערך של 'A' הוא 65, הערך של רווח הוא 32 וכן הלאה. ASCII הוא קידוד 7 ביטים, מה שאומר שהוא משתמש ב128 אפשרויות מתוך 256 האפשרויות שנכנסות בbyte.
הבעיה עם אסקי היא שהוא לא כולל תווים של שפות אחרות – קירילית ועברית למשל.
Code page
הפתרון המתבקש הוא להשתמש בערכים 128-255 כדי לייצג את האותיות החסרות.
הבעיה היא שהרבה אנשים חשבו על הפתרון הזה בו זמנית, ומטבע הדברים היו הרבה טבלאות כאלו, לפעמים אפילו כמה בתוך אותה מדינה.
לא נחמד, כי מסמך שנכתב תוך שימוש בטבלא אחת לא הוצג כמו שצריך למי שהשתמש בטבלא אחרת.
בשלב מסויים הוגדרו סטנדרטים על ידי ארגון התקינה האמריקאי (ANSI) , שנקראו Code pages, מה שעזר למנוע הווצרות של טבלאות מיותרות חדשות.
הבעיה העיקרית עם הפתרון הזה הוא שאי אפשר לערבב שפות שמשתמשות בקודים שונים.
בנוסף, הוא נותן פתרון רק לשפות בעלות פחות מ128 אותיות.
באסיה הוגדר תקן בשם DBCS – Double byte character set, שנועד לתת פתרון לשפות האסיאתיות.
התקן הזה השתמש בקידוד באורך משתנה: חלק מהתווים היו באורך בייט אחד וחלק באורך שני בייטים, ובאופן כללי היה מבלבל למדי.
UNICODE
יוניקוד הוא שם הקוד לטבלא גדולה מאוד שמתאימה מספר לכל אות ידועה (וגם כמה משפות מומצאות כמו קלינגונית), מכיוון שיש טבלא אחת לכל השפות – אין בעיה לערבב בין שפות שונות.
מיתוס נפוץ הוא שניתן לייצג כל אות ביוניקוד בעזרת מספר בין 16 סיביות (או במילים אחרות, שיש פחות מ65536 אותיות ביוניקוד).
זה לא נכון, ולמעשה יש ביוניקוד גרסא 4.0 קרוב ל240,000 סימנים, מה שאומר שצריך לפחות 3 בתים כדי למספר את כל התווים ביוניקוד.
מחרוזת ביוניקוד היא בסך הכל סדרה של מספרים, כאשר כל מספר הוא המיקום של אות מסויימת בטבלא.
מקובל לסמן תו יוניקוד בסימן כמו U+0041, כאשר U+ אומר שזה יוניקוד והמספר שאחריו הוא קוד האות בבסיס הקסדצימלי.
לא במקרה, 128 התווים הראשונים ביוניקוד הם בדיוק אותם 128 התוים הראשונים באסקי וברוב קידודי הCode page.
המחרוזת hello ביוניקוד תכתב ככה:
U+0048 U+0065 U+006C U+006C U+006F
אם נשמור את זה, נקבל:
[code]
00 48 00 65 00 6C 00 6C 00 6F
[/code]
או
[code]
48 00 65 00 6C 00 6C 00 6F 00
[/code]
תלוי בשיטת בה אנחנו מקודדים ספרות בזכרון המחשב (Little endian או Big endian).
כדי להבחין בין שתי השיטות ישנה תוספת של התווים FE FF בתחילת מחרוזת יוניקוד (שתראה ככה או הפוך, לפי הEndianness של המכונה).
הסימון הזה נקרא Unicode Byte Order Mark, או בקיצור BOM – והוא גורם ללא מעט צרות לדפדפנים שכתובים רע.
UTF-8
באו האמריקאים ושאלו, מה אנחנו צריכים את האפסים האלו באמצע המחרוזת? הרי המחרוזת תופסת פי שתיים, והם גם מבלבלים תוכנות שמתייחסות ל0 בתור סימון לסוף המחרוזת (מקובל בC וC++).
וככה נולד UTF-8.
UTF-8 הוא שיטה לקידוד יוניקוד בקידוד בעל אורך משתנה.
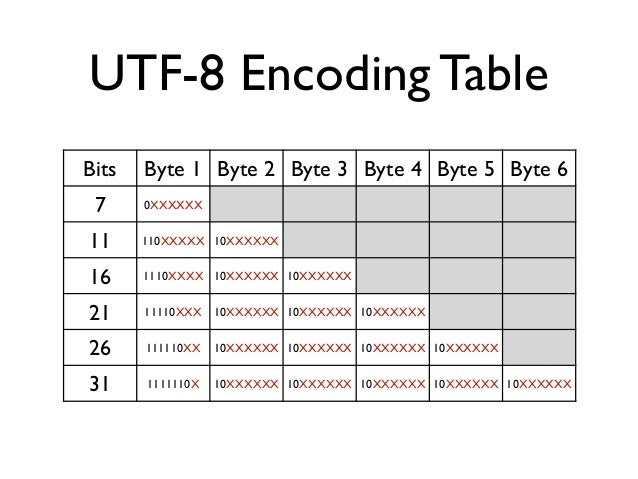
כשקוראים UTF-8, מסתכלים על התו הראשון ולפי הביטים הראשונים אפשר לדעת בדיוק על כמה בתים האות הבאה יושבת.
UTF-8 הפך לסטנדרט המקובל ביותר לקידוד מחרוזות יוניקוד.
PHP ויוניקוד
PHP התמיכה של PHP 4 ו5 ביוניקוד חלקית ביותר.
מחרוזות בPHP הן בעצם סדרה של בייטים ולא יותר ולמרות שתמיד אפשר להשתמש במחרוזת PHP כדי לשמור מחרוזות בקידודים שונים – רק במקרה שהPHP קומפל עם תמיכה בmb_string יהיו לנו פונקציות מיוחדות לטיפול במחרוזות מרובות בתים.
פתרון נוסף הוא להשתמש בספריה iconv, שמוסיפה לPHP יכולות המרה של קידודים, אבל היא לא מגיעה כברירת מחדל עם PHP ומי שרוצה תוכנה שתוכל לרוץ בקלות בכל מחשב ימנע ממנה.
בPHP 6 שמתבשל לאיטו צפויה תמיכה ביוניקוד, UTF-8 וכל זה, אבל זה עדיין לא שוחרר, ואם לשפוט לפי הקצב שלוקח לשוק לאמץ את PHP5 – אז PHP6 לא יהיה רלוונטי בשנים הקרובות למי שרוצה לשחרר תוכנה שתרוץ בכל מחשב.
מכיוון שהפונקציות הסטנדרטיות בPHP תומכות בעצם רק בקידוד שבו כל אות תופסת בייט אחד, הן יכולות ליצור בעיות מעניינות.
אם תקבלו מחרוזת שמקודדת בUTF-8, נניח "שלום", ותציגו אותה בדפדפן האורך שלה יהיה 4 אותיות. אם תשתמשו בפונקצית הPHP לחישוב אורך של מחרוזות, תקבלו שהאורך שלה הוא 8 תווים, כי כל אות מקודדת בשני בתים.
אם תנסו את אותו דבר על המחרוזת המעורבת "שלום SHALOM", תקבלו שהאורך הוא 8 + 1 + 6 = 15.
לעומת זאת, אם תשתמשו בmb_strlen תקבלו את האורך הנכון.
בעיה נוספת היא בעיה של חיתוך מחרוזות UTF-8.
אם נשתמש בפונקציה wordwrap לחיתוך מחרוזות UTF8, היא עלולה לחתוך אות בין שני הבתים שלה, ובעצם להעלים אותה. לא נעים.
הפתרון שלי היה לכתוב גרסא של wordwrap שעובדת על מחרוזות UTF-8.
אפשר להבין למה מפתחי PHP מתבלבלים כשהם מתעסקים עם מחרוזות בUTF-8.
המרות וקיבועים
למרות שרוב אתרי האינטרנט בימינו השכילו לעבור לUTF-8 לקידוד של מחרוזות, עדיין יש אתרים מסויימים שמשתמשים בקידודים מבוססי Code page. למשל – מנוע החיפוש של Walla מקודד לפעמים את מילות החיפוש בכתובת בקידוד עברית 1255 (עברית חלונות), ולפעמים בקידוד UTF-8. מאוד נחמד מצידם של המפתחים לפחות להעביר את הקידוד כחלק מהכתובת (e=hew לעברית 1255 וe=utf לutf8).
לא חסרות דוגמאות אחרות, בעיקר במנועי חיפוש מקומיים (yandex.ru, mail.ru שמשתמשים בקידוד קירילי 1251) ועוד.
מכיון שאני רוצה שמילות החיפוש יוצגו כמו שצריך בFireStats, צריך להמיר את הקידודים האלו לUTF-8.
הבעיה היא שכאמור – אין תמיכה מובטחת בiconv שמאפשר המרות כאלו, ולכן נאלצתי לכתוב בעצמי ספריית המרות קטנה מקידודי codepage כלשהם לקידוד UTF8. הספריה מסתמכת על טבלאות המרה שאפשר להשיג באתר הראשי של יוניקוד.
הרעיון של הספריה הוא להמיר באמצעות הטבלא את המחרוזת ליוניקוד, ואז לקודד אותה לUTF8.
וזו האגדה על אסקי יוניקוד וUTF-8.

Loading ...
Loading ...
קריאה נוספת
Joel on software במאמר מצויין על יוניקוד
מצגת על השרדות עם UTF-8
שאלות נפוצות על יוניקוד וUTF-8 בלינוקס ויוניקס
Unicode Introduction and Resources