לפני קצת יותר משנה גוגל שחררו ברשיון קוד פתוח פרוייקט בשם Protocol Buffers, ובקיצור protobuf.
protobuf מגדיר שפה להגדרת מבני נתונים (IDL), ויודע לייצר קוד יעיל שקורא וכותב את אותם מבני נתונים בC++, JAVA או פייתון.
יש תמיכה חיצונית לפורמט בשפות נוספות, C#, D, רובי PHP* ועוד.
הדוגמאות שאני אתן יהיו בג'אווה, אבל השתמשתי בו גם עם C++ והוא עובד היטב גם שם.
כל מפתח מגיע מתי שהוא לשלב שבו תוכנית שהוא כותב צריכה להעביר נתונים לתוכנית אחרת (או למופע אחר של עצמה) דרך הרשת, או לשמור נתונים לקובץ כדי לקרוא אותם אחר כך.
מקובל לקודד את הנתונים בתוך הודעות, כשיש הרבה מאוד דרכים לכתוב את ההודעות, ובדרך כלל מדובר בקוד די סיזיפי שחוזר על עצמו וכתיבתו היא די משעממת (בפעם העשירית שעושים משהו כזה).
נניח שאנחנו רוצים להעביר אובייקט שמייצג אימייל על גבי הרשת (ונתעלם רגע מהפרוטוקולים המקובלים להעברת אימיילים).
לאובייקט אימייל שלנו יש שדה של שולח, אחד או יותר שדות של מקבלים, נושא, טקסט, ואפס או יותר קבצים נלווים ואפילו עדיפות.
אפשר לייצג אותו במבנה הלוגי הזה:
[code lang="java"]
package messages;
message Email
{
enum Priority
{
LOW = 1;
NORMAL = 2;
HIGH = 3;
}
required string from = 1;
repeated string to = 2;
required string subject = 3;
required string message = 5;
repeated Attachment attch = 4;
optional Priority priority = 6;
optional string date = 7;
message Attachment
{
optional string data = 1;
required string name = 2;
}
}
[/code]
מה שיש לנו פה זה הגדרת הודעה תקינה בשפת הIDL של protobuf.
השפה תומכת בהגדרת חבילה (שמתורגמת לpackage בג'אווה ולnamespace בC++), וכן בהגדרות מקוננות של הודעות.
המספרים אחרי כל שורה נקראים טאגים ומשמשים לזיהוי של השדות בפרוטוקול הבינארי, ולכן אחרי שהם נקבעים אי אפשר לשנות אותם.
אפשר לראות שהשפה תומכת בהגדרה של enum, וכן ברשימות של אובייקטים (שיכולים בעצמם להכיל אובייקטים וכן הלאה).
חוץ מטיפוסים שאתם מגדירים, השפה תומכת גם בטיפוסים פנימיים למשל מחרוזת, משתנה בוליאני, מספר ברוחב קבוע (למשל ארבעה בתים), מספר ברוחב משתנה ועוד.
המספרים ברוחב משתנה מקודדים בצורה דומה קצת לקידוד של UTF8, אבל בצורה קצת יותר פשוטה:
הביט השמאלי (MSB) בכל בייט מוגדר כך: 1 אם המספר המועבר כולל בייטים נוספים, או 0 אם זה סוף המספר.
7 הביטים האחרים בכל בייט משמשים להעברת 7 ביטים של המספר עצמו. בצורה כזו, מספרים קטנים מ128 יתפסו בייט אחד בלבד, מספרים קטנים מ65000 בקירוב יתפסו שני בתים וכן הלאה. אם התוכנית שלכם מעבירה מספרים קטנים שיכולים להיות גדולים לעיתים נדירות – הקידוד הזה הוא אידיאלי כי בדרך כלל המספרים לא יתפסו הרבה מקום, בניגוד לקידוד ברוחב קבוע שבו כל מספר תופס למשל ארבעה בתים.
חלק מהטיפוסים הנתמכים בשפה הם ברוחב קבוע, למשל מספרים בנקודה צפה (Floating point) ושלמים שמוגדרים כFIXED, למשל FIXED64 יהיה תמיד 64 ביטים או 8 בתים.
עוד על השפה אפשר לקרוא פה.
את הקובץ שמכיל את הגדרת ההודעות "מקמפלים" עם protoc, שמייצר ממנו קוד בג'אווה C++ או פייתון:
[CODE]
$ protoc messages.proto –java_out src/
[/CODE]
הנה דוגמא לקוד ג'אווה שמייצר הודעה, כותב אותה לקובץ, קורא אותה ומדפיס אותה בפורמט טקסטואלי:
[CODE LANG="JAVA"]
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import test.Messages.Email;
import test.Messages.Email.Attachment;
import test.Messages.Email.Builder;
class Test
{
public static void main (String args[]) throws FileNotFoundException, IOException
{
Builder b = Email.newBuilder();
b.addTo("test@abc.com");
b.addTo("test@loogle.com");
b.setFrom("someone@there.com");
Attachment aa = Attachment.newBuilder().setName("viruts.exe").build();
b.addAttch(aa);
b.setSubject("A present for you");
b.setMessage("Please open the attached Virus");
Email email = b.build();
System.out.println(email.toString());
FileOutputStream out = new FileOutputStream("email.dat");
email.writeTo(out);
out.close();
System.out.println(Email.parseFrom(new FileInputStream("email.dat")));
}
}
[/CODE]
נקמפל ונריץ:
[code lang="bash"]
$ javac -cp lib/protobuf-java-2.2.0.jar src/Test.java src/test/Messages.java
$ java -cp lib/protobuf-java-2.2.0.jar:src Test
from: "someone@there.com"
to: "test@abc.com"
to: "test@loogle.com"
subject: "A present for you"
attch {
name: "viruts.exe"
}
message: "Please open the attached Virus"
[/code]
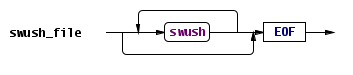
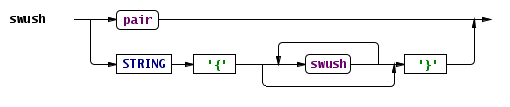
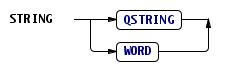
אפשר לראות שבמפתיע הפלט הטקסטואלי הוא כמעט קובץ Swush תקני, אני נשבע שלא הסתכלתי עליו כשהגדרתי את Swush 🙂
זו דוגמא לשימוש בprotobuf בג'אווה, השימוש בC++ בשפות אחרות פשוט בצורה דומה.
כל העניין מאוד קל לשימוש, ואני ממליץ מאוד לכל מי שצריך לכתוב אובייקטים לקובץ או לרשת לבדוק את protobu.
אגב, הקוד המחולל נראה טוב מאוד, כמעט כאילו כתבתם אותו בעצמכם.
* PHP : הספריה לתמיכה בPHP היא pb4php, והיא לא מאוד מוצלחת. למרות שיתכן שבקרוב הפרוייקט יקבל PATCH משמעותי שהופך את הספריה ליותר שמישה (לפחות לצרכים שלי).