הPreprocessror שפיתחתי במסגרת העבודה של בVollee, שנכלל בפרוייקט הקוד הפתוח אנטנה (פרוייקט שעוזר בפיתוח ובבניה של ישומי ג'אווה למכשירים סלולריים), אושר על ידי Eclipse Legal, ויכלל בMTJ.
MTJ הוא פרוייקט Eclipse רשמי שמטרתו להוסיף לEclipse תמיכה בפיתוח ישומי ג'אווה למכשירים סלולריים. כבר היום יש את EclipseME, פלאגין שפותח במשך שנים על ידי קרייג סטרה, שעושה את אותה עבודה – למעשה וקרייג עובד עם צוות MTJ, וMTJ מיועד להיות תחליף רשמי של EclipseME.
תהליך הקליטה של הPreprocessor לא היה קל:
הקוד המקורי הסתמך על ANTLR 2.7 (שמייצר אוטומטית קוד לפענוח קוד לפי הגדרה פורמלית – Parser generator) – הבעיה עם ANTLR 2.7 היתה שהרשיון שלו לא תאם את הרשיון של Eclipse (מסתבר שPublic domain זה לא תמיד טוב מספיק). למרבה המזל, ANTLR 3.0 כבר שוחרר ברשיון BSD שתאם את הרשיון של Eclipse, אבל הוא לא תאם את הקוד של הPreprocessor.
החב'רה בMTJ שאלו אם אני מוכן להמיר את הקוד כך שישתמש בANTLR 3.0: בינתיים עזבתי את Vollee ואת כל העולם של הפיתוח לסלולריים (בשעה טובה ומוצלחת) אז סירבתי, אבל אמרתי שאשמח לייעץ להם ולעזור מרחוק.
הם הרימו את הכפפה, וכמעט בלי עזרה מפתח אחד – דייגו סנדין – המיר את העסק לANTLR 3.0 תוך כשבועיים.
הזמן עבר, ולפני חודשיים צוות MTJ קיבל אישור למסור לי את הקוד, כדי שאקלוט אותו לתוך Antenna.
מכיוון שהקוד כלל בדיקות יחידה מקיפות, שדייגו הקפיד להשתמש בהן כדי לבדוק את ההמרה – התוצאה היתה טובה מאוד.
עוז זמן עבר, והיום הקוד קיבל אישור מEclipse Legal ויכנס לענף הראשי של MTJ.
יבוא SQL ישירות מתוך קוד ג'אווה
כשכותבים בדיקת יחידה (Unit test) לקוד שקשור לבסיס נתונים, צריך לאתחל את בסיס הנתונים לאיזה שהוא מצב ידוע ויציב לפני כל בדיקה.
מול MySQL, אפשר להשתמש בmysql עצמו כדי ליבא סקריפט SQL מוכן, אבל זה לא נחמד במיוחד:
צריך לפתוח תהליך חדש, ויש כל מני בעיות מעצבנות עם זה (בג'אווה למשל, חובה לקרוא את הפלט של התהליך, אחרת הוא יתקע בכתיבה לפלט הסטנדרטי כשיתמלא הבאפר).
הרבה יותר נחמד יהיה ליבא את הקובץ ישירות מתוך ג'אווה, בשימוש בJDBC, לא?
הנה קוד שעושה בדיוק את זה, הוא מקבל זרם קלט (InputStream) שיכול להיות כל דבר, וגם Connection JDBC שחיברתם מבעוד מועד, וקולט את הSQL לתוך בסיס הנתונים.
הקוד מתמודד עם הפלט הסטנדרטי של mysqldump.
[code lang="java"]
public static void importSQL(Connection conn, InputStream in) throws SQLException
{
Scanner s = new Scanner(in);
s.useDelimiter("(;(\r)?\n)|(–\n)");
Statement st = null;
try
{
st = conn.createStatement();
while (s.hasNext())
{
String line = s.next();
if (line.startsWith("/*!") && line.endsWith("*/"))
{
int i = line.indexOf(' ');
line = line.substring(i + 1, line.length() – " */".length());
}
if (line.trim().length() > 0)
{
st.execute(line);
}
}
}
finally
{
if (st != null) st.close();
}
}
[/code]
PHP4 מגיע לסוף החיים, אבל עדיין בשימוש של כ38% מהשרתים
שוחררה הגרסא האחרונה (ככל הנראה) בענף של PHP 4.4.
הגרסא הזו מסמנת את סוף התמיכה הרשמית בPHP4.
PHP5 כבר בחוץ במשך יותר משלוש שנים, אבל עד עכשיו האימוץ שלו היה די איטי, מסיבות של ביצה ודינוזאור:
מפתחי התוכנות לא רצו להפסיק לתמוך בPHP4 כדי לא לאבד משתמשים. חברות אירוח האתרים לא טרחו לשדרג כי כל התוכנות החשובות תמכו גם ככה בPHP4 והמשתמשים, מה איכפת להם?
בשנה שעברה נפתח אתר gophp5.org, ששם לעצמו למטרה לדחוף את האימוץ של PHP5.
הרעיון הוא שאם מסה מספיק גדולה של פרוייקטים תעבור לPHP5, ומסה מספיק גדולה של חברות אירוח תעבור לPHP5, לשאר חברות האירוח לא תהיה ברירה והן תאלצנה לשדרג או לאבד משתמשים, ואז לשאר הפרוייקטים לא תהיה סיבה להשאר בPHP4 והם יוכלו להתחיל סוף סוף לנצל את היכולות של PHP5.
בפברואר 2008 כבר היו מעל 100 פרוייקטי תוכנה שהתחייבו להפסיק לדאוג לתמיכה בPHP4 (זה לא אומר שהם ילכו וישברו את התמיכה בPHP4 בכוונה, פשוט שהם יפסיקו לדאוג שקוד חדש ירוץ בPHP4), ומעל 200 חברות איכסון שתומכות בPHP 5.2 כביררת מחדל וgophp5 טענו להצלחה והפסיקו לאסוף הרשמות.
אז למה לא לתמוך בPHP4? הנה דוגמא מאתמול:
JSON הוא דרך להעביר מבנה נתונים כלשהו לייצוג של מבנה הנתונים כאובייקט ג'אווה סקריפט, והוא אחת הדרכים הפשוטות והיעילות ביותר להעביר נתונים מקוד בצד השרת לדפדפן (שפשוט מפעיל על הטקסט שחוזר את המפסק (parser) של ג'אווה סקריפט כדי לקבל אובייקט מוכן לשימוש.
למרות שראשי התיבות של AJAX הן Asynchronous Javascript And XML, מעולם לא השתמשתי בAJAX כדי להעביר XML, למעשה אני מוצא את הרעיון מזעזע. הרבה יותר קל להעביר JSON, או אפילו קוד HTML ממש.
JSON משמש בהרבה מאוד פרוייקטים מבוססי AJAX, ומכיוון שאין בPHP4 תמיכה מובנית בJSON (אחרי הכל, PHP4 הוא בן שמונה, וJSON הוא די חדש בשכונה) צריך להשתמש בספריות חיצוניות שיודעות להעביר אובייקט PHP לפורמט JSON, אחת הספריות הנפוצות היא Services_JSON (למעשה אני משתמש בספריה הזו בFireStats).
הספריה כתובה בPHP, ולמרות שהיא עובדת נכון, היא לא ממש עובדת מהר, במיוחד כשממירים מבני נתונים גדולים (לא עצומים, משהו בסדר גודל של מערך עם 1000 אובייקטים טיפה מורכבים) לJSON.
ממש אתמול ניסיתי לשפר ביצועים של ישום PHP, אחרי חפירות גיליתי שאחד הדברים שמאטים מאוד את העסק היה המרה של תשובה לדפדפן לJSON בשימוש בServices_JSON, כשאני אומר איטי, אני מתכוון ל8 שניות.
שמונה שניות שהשרת טוחן את הCPU שלו כדי להכין תשובה ללקוח (במקרה הספציפי הזה, במקרים אחרים עם יותר נתונים זה כמובן יותר גרוע).
ברגע שראיתי את זה, לקח לי בדיוק שניה וחצי להיזכר שPHP5 תומך בJSON. בדיקה מהירה בphp.net הניבה את שתי הפונקציות הפשוטות json_encode וjson_decode. החלפתי את השימוש ב Services_JSON בקריאה לפונקציות של php5, ולא הייתי מופתע במיוחד לראות שהמרה של אותו מבנה נתונים לוקחת פתאום 40 מילישניות.
שיפור של פי 200, בזמן עבודה של כמה שניות (טוב, חוץ מלמצוא את הבעיה 🙂 )
השיפור נובע מכך שהתמיכה של PHP בJSON לא כתובה בPHP אלא בC, ולכן היא הרבה הרבה יותר יעילה.
השיפור הזה התאפשר רק כי הפרוייקט הספציפי הזה לא צריך לתמוך בPHP4.
מה אני אצטרך לעשות בFireStats, שעדיין תומך בPHP4 כדי להנות מהשיפור הזה? לבדוק אם אני על PHP5, ואם כן להשתמש בפונקציות האלו אחרת להשתמש בServices_JSON. לא כיף במיוחד.
ואם לא היתה לי סיפריה כמו Services_JSON (כי אין, או כי תנאי הרשיון לא מתאימים לי), הייתי נאלץ לכתוב אחת או פשוט לעבוד בצורה אחרת, פחות נוחה. גם לא כיף.
אז איך מתקדם האימוץ של PHP5?
החל מFireStats 1.3 ששחרתי לפני יותר משנה, FireStats מכילה רכיב ששולח (באישור המשתמש) מידע מערכת אנונימי. חלק מהמידע הוא גרסאות הPHP והMySQL.
הכוונה היא שאני אוכל להשתמש במידע הזה כדי להחליט בצורה יותר מושכלת במה אני צריך לתמוך.
המידע הצטבר לי בבסיס הנתונים, ונכון לכרגע יש לי מידע על כמעט 12000 התקנות. מה שאומר כמעט 12000 שרתים בעולים (אני מתעלם ממקרים של כמה התקנות על אותו שרת).
למי שתוהה, זה לא אומר שFireStats הותקנה 12000 פעמים, אלא ש12000 פעמים המתקינים הסכימו לשלוח מידע מערכת אנונימי.
מי שרוצה את המידע הגולמי מוזמן לקחת אותם מפה (יצוא MSQL, כ5 מגה דחוסים, 65 מגה פרושים).
אז ישבתי כמה שעות כדי להוציא מהנתונים הגולמיים שני גרפים נחמדים:
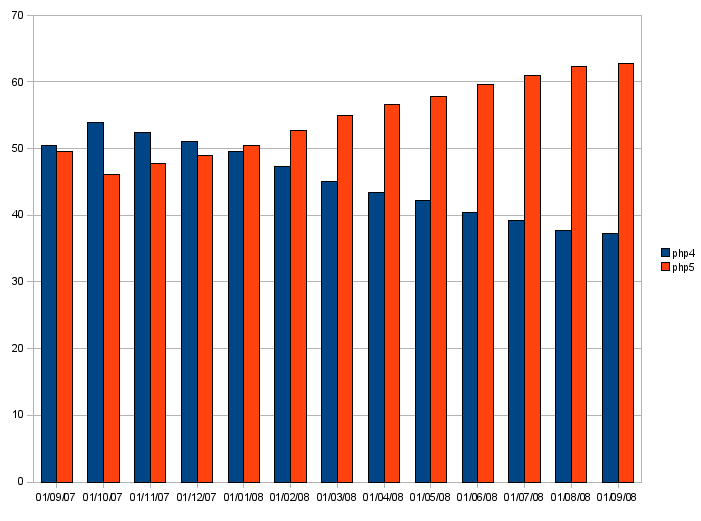
הראשון הוא אחוזי ההתקנות של PHP 4 מול PHP 5, במהלך השנה האחרונה.
למרות שאחוזי ההתקנה של PHP4 ירדו במהלך השנה האחרונה מ52% ל38%, עדיין מי אי אפשר להתעלם ממנו. נקווה שהוא ימות סופית בקרוב:
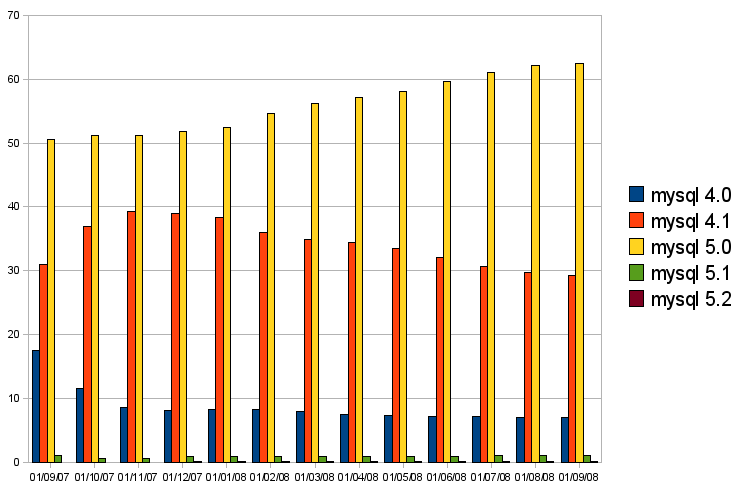
השני הוא אחוזי ההתקנות של הגרסאות המשמעותיות של MYSQL:
כיף לראות שMYSQL 5.0 שולט בשוק, אבל נראה שMYSQL 4.0 הזוועתי נתקע על 7% ולא רוצה למות.
בכל מקרה, MYSQL 4.0 הוא בהחלט מועמד לנטישה, וכבר היום יש לא מעט תכונות חשובות של FireStats שלא נתמכות בגרסא הזו.
משתמש תרם שיפורי ביצועים משמעותיים לIP2C
אם יש משהו שאני אוהב בפרוייקטי קוד פתוח, זה שאנשים מוכנים לפעמים לעבוד די קשה כדי לשפר אותם.
את IP2C, ספריה למציאת המדינה של כתובת IP שחררתי לפני כמעט שנתיים, וכתבתי גם פוסט שמספר על המימוש שלה פה.
IP2C ממומשת בPHP ובג'אווה. מה שמיוחד בה זה שהיא מסוגלת לחפש ישירות על הקובץ, מה שאומר שחיפוש בודד הוא מאוד מהיר כי לא צריך להעלות את כל הקובץ לזכרון.
הייתי לגמרי מרוצה מהביצועים של הספריה בPHP (כ1200 חיפושים בשניה במחשב האחרון שמדדתי), אבל הביצועים בג'אווה היו טובים יותר משמעותית – כ8000 חיפושים בשניה על אותו מחשב בעבודה ישירות על קובץ הנתונים.
ההבדל בביצועים בין PHP לג'אווה לא הטריד אותי, כי היה לי ברור שPHP תהיה יותר איטית מג'אווה, אבל הוא כן הטריד את תומס רומר שהתיישב על העסק לילה שלם ושיפור את הביצועים של גרסאת הPHP ב150%.
תומס כתב פוסט מעניין על השינויים שהוא עשה, ושלח לי את השינויים. שבמבט ראשון נראים טובים ואני אקלוט אותם לפרוייקט אחרי בדיקה מעמיקה יותר.
בנוסף דיברנו קצת בIRC, והוא יעבוד על תמיכה בבסיס הנתונים של software77 :
software77 מספקים בסיס נתונים של IP למדינה, שאמור להיות יותר איכותי מבסיס הנתונים שIP2C משתמשת בו כרגע (webhosting.info), אבל יש להם קצת בעיות בעקביות המידע.
התחלתי לעבוד על תמיכה בבסיס הנתונים שלהם לפני כמה חודשים טובים, אבל כשראיתי שזה נמשך יותר מדי הקפאתי את העסק (שעדיין נמצא בTODO שלי, קבור איפשהו 🙂 )
תומס ימשיך מאיפה שהפסקתי.
EBuild
הפוסט הזה מיועד למתכנתי ג'אווה שעובדים עם Eclipse.
אז אתם מתחילים פרוייקט, מפתחים, משתמשים בכל מני JARים מפרוייקטים אחרים בתוך הסביבת עבודה, מוסיפים פרוייקטים אחרים לרשימת התלויות של הפרוייקט שלכם, והכל עובד בתוך Eclipse.
ואז אתם צריכים לשחרר JAR שירוץ מחוץ לסביבת הפיתוח שלכם.
פה יש כמה אפשרויות:
1. להשתמש באופצית הExport JAR של Eclipse.
2. ליצור build.xml לפרוייקט
לפרוייקטים פשוטים, האפשרות הראשונה תספיק, אבל היא בהחלט לא עושה נעים בבטן. כדי ליצור את הJAR חייבים את Eclipse, וזה לא מאוד מיקצועי.
האפשרוית השניה היא מה שכמעט כולם עושים:
בדרך כלל מעתיקים build.xml מהפרוייקט השכן, ומתחילים לעקם אותו עד שיתאים לפרוייקט הנוכחי.
על הדרך עוד פעם מוסיפים – הפעם לbuild.xml החדש – את המסלול לJARים שהפרוייקט צריך כדי להתקמפל, ואולי גם את המסלול לספריות הbin של פרוייקטים אחרים שהפרוייקט הזה צריך, או אולי פשוט קריאה לקובץ הbuild.xml של הפרוייקטים האלו, ואז שימוש בתוצרים שלו.
אחרי זמן שיקח בין חצי שעה לחצי יום, תלוי בבלאגן שיש לכם בפרוייקט, כנראה תהיה לכם מערכת build עובדת לפרוייקט, שעושה בדיוק מה שאתם רוצים.
תהיה לכם תחושה נעימה בבטן, כי תוכלו לבנות את הפרוייקט שלכם מחוץ לEclipse (וככה גם אחרים אם בניתם את העסק נכון).
אבל מה, הפרוייקט ממשיך לחיות:
עם הזמן, נוספים לו תלויות בJARים נוספים, תלויות בפרוייקטים נוספים בסביבת העבודה וכו', ואז מערכת הבילד המדוגמת שלכם נשברת, ואתם מרגישים פיכס, כי שוב אי אפשר לבנות את העסק מחוץ לEclipse עד שתתקנו את הבילד.
הפעם בדרך כלל העידכון של הבילד הוא יותר פשוט, כמה דברים קטנים והכל עובד שוב.
עכשיו, תכפילו את כל העסק הזה במספר הפרוייקטים שאתם מפתחים אקטיבית על פני כמה שנים, ומתחיל להיות פה משהו די מעצבן.
הרבה קבצי build.xml שעושים כמעט אבל לא בדיוק את אותו דבר, והרבה התעסקות איתם ברגע שמשהו משתנה.
המפתח העצלן כבר מזמן שאל את עצמו: "מה, אין דרך אחרת?"
הרי לרוב הפרוייקטים, Eclipse מכיל את כל המידע שצריך בשביל לבנות אותם.
מעבר לזה, המידע הזה תמיד נכון בהגדרה כי אחרת לא תוכלו לפתח כלום וזה יהיה הדבר הראשון שתתקנו ברגע שתעשו איזה שינוי.
Eclipse שומר את רוב המידע בתוך קבצי ה.claspath בתוך כל פרוייקט (וגם קצת בתוך קבצי ה.project). הקבצים האלו הם קבצי XML פשוטים למדי, שלא השתנו משמעותית מאז ימי Eclipse הראשונים.
אז הנה רעיון:
מה אם במקום לשכפל את המידע גם בEclipse וגם בbuild.xml, ניצור build.xml אחד שקורא את המידע על הפרוייקטים מEclipse, מבין מה סדר הבניה הנכון של הפרוייקטים, איזה JARים צריך לכל פרוייקט ובונה את העסק לפי זה?
אותו build.xml קסום ומופלא יעבוד כמעט לכל פרוייקט Java שפותח בתוך Eclipse בצורה שקופה, בלי שום התעסקות ותחזוקה של קובץ build.xml ספציפי לפרוייקט.
נשמע טוב מכדי להיות אמיתי?
ובכן, שחררתי מערכת כזו בדיוק, ולמערכת קוראים ebuild.
התחלתי לפתח אותה לפני שנים, והיא ליוותה אותי דרך ארבע מקומות עבודה עד עכשיו (למעשה דרך כל מקומות העבודה שהיו לי בתחום ההיטק).
המערכת משוחררת תחת רשיון FreeBSD (רשיון תעשו מה שבזין שלכם, לא מזיז לי) ודף הבית שלה הוא http://ebuild.firefang.net.
בגדול, כדי להשתמש בה, מה שצריך לעשות זה:
- לקחת את הקוד שלה ולהכניס לפרוייקט נפרד בסביבת העבודה.
- להעתיק את example-common.properties לcommon.properties (הוא מכיל הגדרות ספציפיות למחשב שלכם, למרות שכרגע אין מה להתעסק איתו ברוב המקרים).
- ליצור קובץ build.properties בתוך הפרוייקט שאתם בונים (מאוד פשוט ומינימלי)
- להריץ עם ant -Dproject=YOUR_PROJECT, כאשר YOUR_PROJECT הוא השם שם הפרוייקט שלכם בסביבת העבודה.
- לקחת את התוצרים האיכותיים מספרית הbuild שנוצרה תחת הפרויקט.
התוצר יהיה JAR שניתן להריץ בעזרת java -jar file.jar, וכן זיפ שכולל את הJAR ואת הספריות הדרושות כדי להפיץ את התוכנית.
נכון לכרגע, המערכת די בסיסית ומסוגלת לבנות פרוייקטי Eclipse בתוך סביבת העבודה (Workspace) שלכם.
בהמשך אני מתכנן להוסיף אפשרות לתייג פרוייקטם ולבנות ישר מCVS/SVN בלי לגעת בקוד בסביבת העבודה (זה דרוש כדי לשחרר גרסאות בצורה מסודרת).
בנוסף, אני מתכנן להוסיף אפשרות לebuild-hook.xml אופציונלי שיהיה ספציפי לפרוייקט שיכיל כל מני דברים שבאמת ספציפיים לפרוייקט מסויים.
יש כמה דברים שכדאי לדעת:
באופן כללי, עדיף לעבוד עם JARים שנמצאים בתוך בworkspace כי אז החיים של מי שרוצה לבנות את העסק הם יותר קלים.
- ebuild תומך בזה בצורה טובה, אבל לא ברור לי אם הוא יתמודד עם JARים חיצוניים.
- ebuild לא תומך בכל מני הרחבות מוזרות של eclipse, שמסתמכות על מידע שלא מופיע בקבצי ה.classpath. למשל 'user libraries'. אם אתם רוצים שהוא יעבוד בשבילכם, תעבדו פשוט.
זהו.
אני אשמח אם הרבה אנשים ישתמשו בebuild, ידווחו על בעיות ואולי אפילו ישלחו תיקונים.
MySQL optimization
לפני כמה שבועות פרסמתי פוסט על אופטימיזציות.
הנה ההמשך.
דוגמא מעשית, שיפור ביצועים של שאילתות בFireStats (לגרסא 1.6)
מנגנון מקובל לשיפור ביצועים הוא מטמון (cache). הרעיון פשוט : בפעם הראשונה ששואלים אותנו משהו אנחנו מחשבים אותו וזוכרים את התוצאה. בפעם השניה אנחנו משתמשים בתוצאה שחישבנו קודם.
כשבודקים ביצועים, חשוב לוודא שהבדיקה נותנת תוצאות זהות בשתי הרצות שונות. במקרים רבים יש מנגנוני מטמון יגרמו לבדיקה לרוץ הרבה יותר מהר בפעם השניה, ובדרך כלל הם רק מפריעים בסיטואציות של בדיקת ביצועים כי אנחנו רוצים למדוד את השיפור שנובע מהקוד שלנו, ולא מזה שהCache הכיל את התוצאה שכבר חישבנו בהרצה הראשונה.
דוגמא לכך היא הCache של MySQL: ההרצה השניה של שאילת תמיד תהיה הרבה יותר מהירה מההרצה הראשונה, כי MySQL זוכר את התוצאות מהפעם הראשונה ואם שום דבר בנתונים לא השתנה הוא פשוט מחזיר את אותה תוצאה.
כדי לבטל את אותו Cache, אפשר להשתמש בפקודת הMySQL:
[code lang="sql"]
SET GLOBAL query_cache_size = 0;
[/code]
FireStats תומך בגרסאות MySQL ממשפחת 4.0, 4.1 ו5.0, כאשר ההבדל בין 4.0 ל4.1 כל כך משמעותי שיש שאילתות בFireStats שכתובות אחרת לכל אחת מהגרסאות.
נסיון לשיפור ביצועים, במיוחד כזה שמבוסס על שינויים בסכמת הנתונים יצריך שינויים בקוד שמטפל ב4.0 ובקוד של 4.1, לכן כדאי לבדוק שהכל עובד על השרת הרלוונטי. בנוסף, מכיוון שרוב (60%) משתמשי FireStats עובדים עם MySQL 5.X, כדי גם לבדוק את השיפור על השרת הזה.
כדי לבצע את זה, הרמתי שלושה שרתי MySQL, נציג אחד מכל משפחת גרסאות, והכנסתי לכל שרת חבילת נתונים די כבדה (וזהה בין השרתים) שמבוססים על סטטיסטיקות מהשרת שלי.
ובכל אחד מהשרתים ביטלתי את מטמון השאילתות (query_cache_size).
יצרתי טבלא בגנומטיק (כמו אקסל), שנראית ככה (תת טבלא כזו לכל בדיקה שאני רוצה)

נניח שהפונקציה שאני רוצה לשפר היא:
[code lang="php"]
function foo()
{
$sql = "SELECT * from …";
return query($sql);
}
[/code]
קודם כל הכפלתי את הקוד והוספתי הדפסה של שאילת הSQL שנשלחת לשרת:
[code lang="php"]
function foo()
{
if (true) // old code
{
$sql = "SELECT * from …";
echo $sql; return;
return query($sql);
}else{
$sql = "SELECT * from …";
echo $sql; return;
return query($sql);
}
}
[/code]
מכאן זו היתה שיטת העבודה:
1. הרצה של הקוד במצב הישן.
2. העתקה של השאילתה שהודפסה, והרצה שלה ישירות על כל אחד משלושת בסיסי הנהנתונים. ושמירה של הזמן שנדרש בטבלא מסודרת.
3. מעבר למצב חדש (פשוט לשנות את הfalse לtrue בראש הפונקציה), אופטימיזציה של השאילתה וחזרה על הבדיקה מול כל אחד מהשרתים, ושוב שמירה של התוצאות בטבלא, הפעם בעמודה של תוצאות אחרי אופטימיזציה.
העבודה השיטתית עזרה לי לא לשכוח דברים תוך כדי, ולוודא שאכן שיפרתי את התוצאות לפני שאני רץ להכניס את הקוד למערכת.
בנוסף, מכיוון שגם הקוד החדש וגם הישן היו לי מול העיניים, יכלתי לוודא שהם עושים בדיוק את אותו דבר.
חשוב לשים לב שלא ערבבתי אופטימיזציה של קוד הPHP עם שאילות הMYSQL. זה מבלבל מספיק גם ככה.
אז מה בעצם עשיתי?
פיירסטטס תומך בכמה אתרים בו זמנית, ולכן יש בו מזהה אתר. בהתחלה שמרתי את מזהה האתר בטבלאת הכניסות, בשלב מסויים הבנתי שאני צריך מזהה אתר גם בטבלאת הכתובות (URLים), כי הרי כל URL שיך לכל היותר לאתר אחד.
אז הוספתי את העמודה, אבל שכחתי למחוק את העמודה מטבלאת הכניסות.
מצב כזה של כפילות נתונים הוא לא מומלץ לפי הגישה המקובלת בתכנון בסיסי נתונים, כי הוא מאפשר מצבים של חוסר עקביות במידע.
באחת הגרסאות האחרונות של פיירסטטס תיקנתי את המעוות: הסרתי את העמודה מטבלאת הכניסות ותיקנתי את כל הקוד שהושפע מזה לבצע join עם טבלאת הכתובות כשהוא צריך גישה לאתר.
על פניו הדבר הנכון לעשות: אבל זה יצר בעיה חדשה:
כמעט כל השאילתות דרשו עכשיו join נוסף. עבור משתמשים עם בסיסי נתונים קטנים (נניח עד חצי מליון כניסות בטבלאת הכניסות ועד 50 אלף כתובות בטבלאת העסק עבד סביר, אבל עבור משתמשים עם בסיסי נתונים גדולים יותר העומס על השרת התחיל לגדול בצורה חדה ככל שנפח הנתונים עלה.
הפתרון שלי הוא לחזור בי מהדבר "הנכון" שעשתי קודם, כלומר להחזיר את עמודת הsite_id לטבלאת הכניסות, שתשמש לצרכי פילטור בזמן השאילות כדי להמנע מהjoin עם טבלאת הכתובות.
שיפור נוסף נבע משינוי מבני של השאילות ככה שיעבדו בצורה יותר יעילה.
כדי לעשות את זה, חשוב להבין מה עושה בסיס הנתונים כדי לחשב את השאילתה.
לשם כך אפשר להשתמש בפקודה explain, שמחזירה תיאור של האסטרטגיה שבה בסיס הנתונים יחשב את התוצאות.
explain מחזיר תוצאות די קריפטיות, לא משהו שתבינו בלי לקרוא את התיעוד.
בכך מקרה, חשוב לשים לב לעובדות הבאות:
בכל שלב, MySQL משתמש באינדקס אחד בלבד לכל היותר (אם יש אינדקס מתאים). ככל שהאינדקס יהיה יותר ספציפי ככה הביצועים יכולים להיות טובים יותר.
(יתכן שגרסאות עתידיות של MySQL ידעו להשתמש בכמה אינדקסים בשלב, אבל לדעתי זה עדיין לא פה).
ככה נראית הטבלא שלי אחרי שמילאתי אותה:
| Query name | MySQL Version | 4.0.17 | 4.1 | 5.0.51 | |
| Num page views for all hits in site=1 | Original query time sec | 1.20 | 0.93 | 0.84 | |
| Optimized query time sec | 0.10 | 0.06 | 0.06 | ||
| Improvement % | 91.67% | 93.55% | 92.86% | ||
| Num page views for all hits in all sites | Original query time sec | 1.17 | 0.91 | 0.84 | |
| Optimized query time sec | 0.11 | 0.08 | 0.08 | ||
| Improvement % | 90.60% | 91.21% | 90.48% | ||
| Num page views for for last last 14 days for all sites | Original query time sec | 0.19 | 0.16 | 0.16 | |
| Optimized query time sec | 0.12 | 0.09 | 0.11 | ||
| Improvement % | 36.84% | 43.75% | 31.25% | ||
| Num all unique visitors for site_id = 1 | Original query time sec | 2.93 | 1.24 | 1.13 | |
| Optimized query time sec | 1.75 | 0.68 | 0.72 | ||
| Improvement % | 40.27% | 45.16% | 36.28% | ||
| Num all unique visitors for all sites | Original query time sec | 2.09 | 1.24 | 1.15 | |
| Optimized query time sec | 1.26 | 0.47 | 0.47 | ||
| Improvement % | 39.71% | 62.10% | 59.13% | ||
| Num unique visitors for last 14 days for all sites | Original query time sec | 0.32 | 0.18 | 0.18 | |
| Optimized query time sec | 0.28 | 0.16 | 0.15 | ||
| Improvement % | 12.50% | 11.11% | 16.67% | ||
| Recent referrers for all sites | Original query time sec | 2.54 | 3.01 | 3.01 | |
| Optimized query time sec | 2.30 | 1.54 | 1.78 | ||
| Improvement % | 9.45% | 48.84% | 40.86% | ||
| Recent referrers for site_id = 1 | Original query time sec | 2.48 | 2.71 | 2.76 | |
| Optimized query time sec | 2.65 | 1.65 | 1.90 | ||
| Improvement % | −6.85% | 39.11% | 31.16% | ||
| Search terms for site_id = 1 | Original query time sec | 1.67 | 2.14 | 2.75 | |
| Optimized query time sec | 1.67 | 0.84 | 0.91 | ||
| Improvement % | Not optimized | 60.75% | 66.91% | ||
| Popular pages (all) | Original query time sec | 1.88 | 4.67 | 4.80 | |
| Optimized query time sec | – | 1.73 | 1.96 | ||
| Improvement % | Not optimized | 62.96% | 59.17% | ||
| Popular pages (site_id = 1) | Original query time sec | 1.93 | 4.07 | 4.09 | |
| Optimized query time sec | – | 1.88 | 2.11 | ||
| Improvement % | Not optimized | 53.81% | 48.41% | ||
| get questagents (180 days, site_id = 1) | Original query time sec | 6.89 | 2.90 | 2.35 | |
| Optimized query time sec | 5.07 | 1.00 | 1.10 | ||
| Improvement % | 26.42% | 65.52% | 53.19% | ||
| Countries (20 countries, 180 days, site_id = 1) | Original query time sec | 1.95 | 1.08 | 1.08 | |
| Optimized query time sec | 0.30 | 0.20 | 0.23 | ||
| Improvement % | 84.62% | 81.48% | 78.70% | ||
| Hits table (100) | Original query time sec | 0.30 | 0.61 | 0.42 | |
| Optimized query time sec | – | – | – | ||
| Improvement % | Not optimized | Not optimized | Not optimized | ||
MySQL and the number of the beast
מי שמצליח להצדיק את התוצאה הזו מMySQL יזכה בחופשה בקאריבים:
[code lang="sql"]
create table t(a varchar(10));
insert into t(a) values('aaa'),('bbb'),('ccc'),('ddd');
select * from t where a in (666,'a');
+——+
| a |
+——+
| aaa |
| bbb |
| ccc |
| ddd |
+——+
[/code]
C יותר מהירה מJava
כולם יודעים שC יותר מהירה מג'אווה, נכון?
פרוייקטים רציניים של גריסת מספרים (Number crunching) כמו עיבוד תמונה בזמן אמת, זיהוי קול, רינדור, דחיסה, קידוד ווידאו וכו בדרך כלל נכתבים בC (או C++).
בהינתן שתי פיסות קוד שעושות בדיוק את אותו דבר, מעניין לראות את במה מתבטא היתרון של C על ג'אווה.
למה אפשר לצפות ליתרון?
כי ג'אווה רצה מעל JVM, והJVM מוסיף תקורה, ברור שC תרוץ יותר מהר כי היא רצה ישר על הCPU ולא דרך הJVM.
הנה שתי פיסות קוד, אחת בג'אווה ואחת בC. שתי התוכניות מאתחלות שתי מטריצות גדולות ומכפילות אותן אחת בשניה, הקוד בהחלט לא יעיל במיוחד ברמת האלגוריתם, אבל הוא זהה מבחינה מימושית.
הנה הקוד:
תוכנית C:
[code lang="c"]
#include
#include
int main(int argc, char **argv)
{
int i,j,k;
int N = 2500;
printf("N = %d\n", N);
double *A = malloc(N*N*sizeof(double));
double *B = malloc(N*N*sizeof(double));
double *C = malloc(N*N*sizeof(double));
double *bj = malloc(N*sizeof(double));
for (i = 0; i < N; i++)
for (j = 0; j < N; j++)
{
int n = i*N+j;
A[n] = i * j;
}
for (i = 0; i < N; i++)
for (j = 0; j < N; j++)
B[i*N+j] = i * j * j;
// order 7: jik optimized ala JAMA
for (j = 0; j < N; j++) {
for (k = 0; k < N; k++)
bj[k] = B[k*N+j];
for (i = 0; i < N; i++) {
double s = 0;
for (k = 0; k < N; k++) {
s += A[i*N+k] * bj[k];
}
C[i*N+j] = s;
}
}
printf("done\n");
return 0;
}
[/code]
תוכנית ג'אווה:
[code lang="java"]
public class Matrix
{
public static void main(String[] args)
{
int i,j,k;
int N = 2500;
System.err.println("N = " + N);
double A[] = new double[N*N];
double B[] = new double[N*N];
double C[] = new double[N*N];
double bj[] = new double[N];
for (i = 0; i < N; i++)
for (j = 0; j < N; j++)
{
int n = i*N+j;
A[n] = i * j;
}
for (i = 0; i < N; i++)
for (j = 0; j < N; j++)
B[i*N+j] = i * j * j;
// order 7: jik optimized ala JAMA
for (j = 0; j < N; j++) {
for (k = 0; k < N; k++)
bj[k] = B[k*N+j];
for (i = 0; i < N; i++) {
double s = 0;
for (k = 0; k < N; k++) {
s += A[i*N+k] * bj[k];
}
C[i*N+j] = s;
}
}
System.err.println("done");
}
}
[/code]
מי לוקח התערבות של בכמה C עוקפת את ג'אווה בזמן הריצה של זה?
נקמפל ונבדוק:
[code]
$javac Matrix.java
$gcc Matrix.c -o matrix
$ date;java Matrix;date;./matrix;date
Thu Jun 26 08:42:10 IDT 2008
N = 2500
done
Thu Jun 26 08:42:54 IDT 2008
N = 2500
done
Thu Jun 26 08:44:31 IDT 2008
[/code]
לתוכנית בג'אווה לקח לקח 44 שניות ולתוכנית בC לקח 107 שניות.
מש"ל.
אה, רגע. רצינו להראות שC יותר מהירה!
טוב, מסתבר שלא כדאי לקחת דברים כמובנים מאליהם, גם אם כולם יודעים שהם נכונים.
אם אתם חושבים שרימיתי, תריצו בעצמכם. בדקתי על שני מחשבים, אחד עם שתי ליבות של 3GHZ, ואחד עם ארבע ליבות של 2.4GHZ (כמובן שהראשון הוביל בכמה אחוזים טובים, אבל היחס נשמר).
השתמשתי בJava 1.6.06.
לדעתי התופעה הזו נובעת מההתקדמות המדהימה של סביבת הריצה של ג'אווה בתחום הHotspot.
Hotspot היא טכנולוגיה שמקמפלת חלקים "חמים" בתוכנית בזמן, אבל בזמן ריצה. מכיוון שזמינות לHotspot סטטיסטיקות בזמן הריצה הממשי של התוכנית היא יכולה לשנות את הקוד ככה שירוץ בצורה אופטימלית לאור התנהגות של התוכנית ולא כנסיון מלומד לנחש מה יהיה יותר מהר מהתבוננות ושינוי הקוד, מה שעושה קומפיילר סטאטי.
עדכון:
קימפלתי את התוכנית C עם אופטימיזציה מקסימלית והתוצאה שלה השתפרה פלאים:
[code]
gcc -O3 Matrix.c
$ date;./matrix;date
Thu Jun 26 11:26:00 IDT 2008
N = 2500
done
Thu Jun 26 11:26:29 IDT 2008
[/code]
הפעם התוצאה של C היא 29 שניות.
טוב משמעותית מקודם, וגם יותר מהיר בכ30% מג'אווה.
עדכון 2:
שמתי לב שקוד שקומפל עם javac איטי מקוד שקומפל בeclipse. נחשתי שeclipse מקמפל עם jikes (אני לא בטוח בזה).
ניסיתי עם jikes והתוצאה השתוותה, תיקו 29 שניות.
[code]
$ javac Matrix.java ; time java Matrix
N = 2500
done
real 0m42.854s
user 0m55.335s
sys 0m26.214s
$ jikes --bootclasspath /usr/lib/jvm/java-6-sun-1.6.0.06/jre/lib/rt.jar Matrix.java ; time java Matrix
N = 2500
done
real 0m29.463s
user 0m29.366s
sys 0m0.108s
[/code]
אגב, זו תוצאה מדהימה שכדאי שכל מפתח ג'אווה יכיר.
מי רוצה לשפר את התוצאות עוד?
Day of release
בצירוף מקרים קוסמי שחררתי היום גרסאות חדשות לשלושה פרוייקטים בלתי תלויים:
FireStats 1.5.9-RC3:
FireStats 1.5 מתייצב, ורוב הסיכויים שהגרסא הבאה תהיה הגרסא היציבה של הענף הזה.
רשימת השינויים נמצאת כאן.
WPMU Plugin Commander 1.1.0
WPMU Plugin Commander הוא תוסף ניהוי תוספים לWPMU, שמוסיף כמה תכונות מאוד נדרשות לWPMU (אפשרות לבחור איזה תוספים משמשים יכולים להפעיל ולכבות, אפשרות להפעיל אוטומטית תוספים עבור בלוגים חדשים ועוד)
אתמול בלילה קיבלתי תרומת קוד שמוסיפה תמיכה בריבוי שפות לPlugin Commander, וכן שינויי עיצוב שגורמים לא להיות הרבה פחות מכוער.
בנוסף, התורמת של הקוד תרמה גם תרגום לרוסית של התוסף.
Antenna 1.1.0-beta
קיבלתי תרומת קוד גדולה מצוות MTJ, הקוד מממש את הPreprocessor שכתבתי בANTLR 3.0, מה שיאפשר הכנסה של הPreprocesror לתוך MTJ.
MTJ הוא פרוייקט שמטרתו להכניס תמיכה בפיתוח קוד J2ME בEclipse. הפרוייקט יתבסס על EclipseME, שהוא הסטנדרט דה-פקטו לפיתוח J2ME עם Eclipse. הPreprocessor שלי כבר נמצא בתוך EclipseME די הרבה זמן, אבל היתה בעיה עם הרשיון של ANTR 2.7.7 שבו השתמשתי כדי לפתח אותו, ו Eclipse legal לא אישרו את הכנסת הקוד שלי לMTJ מהסיבה הזו.
הצוות של MTJ בחר לבצע Porting של הPreprocessor כך שיעבוד עם ANTLR 3.0 כי הרשיון שלו תואם את זה של Eclipse.
לפני כמה ימים הצוות קיבל אישור מEclipse legal לתת לי את הקוד שהם יצרו כדי שאני אקלוט אותו לתוך Antenna.
הקוד היה איכותי, ועבר את כל בדיקות היחידה שהגדרתי כבר, מה שנתן לי ביטחון גבוה שהוא עובד כמו שצריך. אחרי כמה שעות עבודה, הקוד הוטמע והיום שחררתי גרסא חדשה של Antenna שמשתמשת בPreprocessor החדש כברירת מחדל.
The root of all evil
איכות תוכנה נמדדת בכמה פרמטים:
נכונות (correctness): האם התוכנה עושה מה כל מה שהיא צריכה לעשות, ובצורה נכונה?
קלות תחזוקה (maintainability) : כמה קל למצוא ולטפל בבאגים? כמה קל להרחיב את המערכת?
ביצועים (performance) : האם התוכנה עובדת מהר מספיק?
המדדים האלו נוטים לבוא אחד על חשבון השני.
קוד נכון וקל לתחזוקה הוא בדרך כלל פחות יעיל.
קוד נכון ויעיל הוא בדרך כלל קשה לתחזוקה.
קוד יעיל וקל לתחזוקה.. אין דבר כזה :).
שיפור ביצועים בתוכנה הוא אחד הנושאים שכל מפתח מגיע אליו בשלב מסויים. בדרך כלל מוקדם בהרבה ממה שצריך.
הבעיה עם שיפור ביצועים היא שהוא מעלה את מורכבות הקוד, מה שפוגע אוטומטית בקלות התחזוקה, ומעלה את הקושי בשמירה על נכונות.
חכמים ממני כבר אמרו שאופטימיזציה מוקדמת מדי היא שורש כל רע :
כשמשפרים ביצועים מוקדם מדי, קשה להוסיף אחר כך תכונות נוספות לאפליקציה, כי המורכבות של הקוד עולה.
הבעיה היא שגם שכבר מגיע הזמן לשפר ביצועים, רוב המפתחים מבזבזים את הזמן שלהם בשיפורים חסרי ערך שרק מעלים את מורכבות האפליקציה, תוך רווח שולי מאוד בביצועים, לפעמים רווח כל כך שולי שהוא בלתי מורגש.
כשבאים לשפר ביצועים, חשוב להשקיע את הזמן בשיפורים הנכונים.
הדרך הנכונה היא לא להסתכל על הקוד, למצוא פיסת קוד לא יעילה, לשפר אותה ולהכריז שהאפליקציה עובדת יותר מהר.
הדרך הנכונה היא קודם כל לאתר מועמדים לאוטימיזציה, לא לפי איפה שאפשר לעשות אופטימיזציה אלא לפי איפה שצריך והדרך לשם היא למדוד את ביצועי האפליקציה בטיפול במשימות בעייתיות מבחינת ביצועים (בין אם זה יהיה זמן איתחול, פעולה מסויימת בממשק המשתמש שמרגישה איטית או כל דבר אחר).
כשמודדים, חשוב להבין היטב באיזה חלק של הקוד התוכנית מבלה את רוב הזמן, זאת על ידי מדידות של תתי משימות בתוך אותה משימה בעייתית.
ברגע שהבנו את התנהגות האפליקציה ואיתרנו את הגורם או הגורמים לאיטיות, הגיע הזמן לנסות לשפר את הביצועיים.
בשלב הזה רוב המפתחים פשוט ירוצו וישכתבו חלקים מהקוד כדי לגרום להם לרוץ יותר מהר, בדרך כלל תוך העלאת המורכבות של הקוד. הבעיה היא שגם אם אכן יש שיפור ביצועים – איך נחליט אם הוא מצדיק את השינויים שעשינו?
המשמעות של השינויים האלו, היא כאמור עליה במורכבות הקוד, מה שיקשה עלינו להוסיף תכונות עתידיות לקוד ויקשה עלינו לאתר ולתקן באגים.
אולי השיפור בפועל הוא 2% בלבד ולא מצדיק את המחיר הזה?
כדי להחליט צריך להשוות את הביצועים לפני ואחרי השינוי, ולהחליט אם השיפור מצדיק את השינוי בקוד.
הדרך לעשות את זה היא ליצור בדיקה מוגדרת היטב שניתן להריץ שוב ושוב ולקבל מדידות זמן כמעט זהות בין הרצות שונות, ואז לראות בכמה אנחנו מצליחים לשפר את זמן הריצה של הקוד.
כדאי שהבדיקות יריצו בעיקר קוד אמיתי של התוכנית, למפתחים יש נטיה ליצור בדיקות סינטטיות שמראות שיפורי ביצועיים אסטרונומיים בנקודות מסויימת, אבל בתמונה הכללי הרבה פעמים השיפורים הם הרבה פחות משמעותיים.
דוגמא פשוטה:
קוד אמיתי מהתוכנית
[code lang="java"]
// do stuff
doSomething();
// do more stuff
[/code]
בדיקה סינטטית:
[code lang="java"]
int start = time();
for (int i=0;i<1000000;i++)
{
doSomething();
}
int elapsed = time() - start;
print "average time is " + (elapsed / 1000000);
[/code]
צריך לשים שהבדיקה הסינטטית בודקת תזמון של פעולה אחת בזרימה של התוכנית, ויש עוד פעולות (do stuff וdo more stuff). ככה שגם אם נשפר את הביצועים של הבדיקה ב90% - אם הפעולות האחרות לוקחות בסך הכל שניה, וdoSomething לוקחת 10 מילישניות אז השיפור הוא זניח במקרה הזה.
בפוסט הבא בסדרה הזו אני אתאר דוגמא מעשית של אופטימיזציה של שאילתות MySQL