פיטר ברייט במאמר מרתק בארס-טכניקה על המעבר שלו מפיתוח לWin32 לפיתוח Cocoa (הAPI של Max OS X).
המאמר כולל סקירה היסטורית והשוואה של XP לMaxOS X; דוט-נט – הנסיון של מייקרוסופט להפוך את הAPI שלה למודרני. ועוד.
עדיין לא קראתי את כולו, אבל בינתיים הוא מרתק.
המאמר מחולק לשלוש חלקים:
חלק ראשון
חלק שני
חלק שלישי
יוניקוד ודגים אחרים
הערה: יש סקר בסוף.
סקירה היסטורית
בראשית היה ASCII (האמת היא שהיו קידודים לפני ASCII אבל הם לא מעניינים אותנו).
אסקי נועד בעיקר לתווים באנגלית, הערך של 'A' הוא 65, הערך של רווח הוא 32 וכן הלאה. ASCII הוא קידוד 7 ביטים, מה שאומר שהוא משתמש ב128 אפשרויות מתוך 256 האפשרויות שנכנסות בbyte.
הבעיה עם אסקי היא שהוא לא כולל תווים של שפות אחרות – קירילית ועברית למשל.
Code page
הפתרון המתבקש הוא להשתמש בערכים 128-255 כדי לייצג את האותיות החסרות.
הבעיה היא שהרבה אנשים חשבו על הפתרון הזה בו זמנית, ומטבע הדברים היו הרבה טבלאות כאלו, לפעמים אפילו כמה בתוך אותה מדינה.
לא נחמד, כי מסמך שנכתב תוך שימוש בטבלא אחת לא הוצג כמו שצריך למי שהשתמש בטבלא אחרת.
בשלב מסויים הוגדרו סטנדרטים על ידי ארגון התקינה האמריקאי (ANSI) , שנקראו Code pages, מה שעזר למנוע הווצרות של טבלאות מיותרות חדשות.
הבעיה העיקרית עם הפתרון הזה הוא שאי אפשר לערבב שפות שמשתמשות בקודים שונים.
בנוסף, הוא נותן פתרון רק לשפות בעלות פחות מ128 אותיות.
באסיה הוגדר תקן בשם DBCS – Double byte character set, שנועד לתת פתרון לשפות האסיאתיות.
התקן הזה השתמש בקידוד באורך משתנה: חלק מהתווים היו באורך בייט אחד וחלק באורך שני בייטים, ובאופן כללי היה מבלבל למדי.
UNICODE
יוניקוד הוא שם הקוד לטבלא גדולה מאוד שמתאימה מספר לכל אות ידועה (וגם כמה משפות מומצאות כמו קלינגונית), מכיוון שיש טבלא אחת לכל השפות – אין בעיה לערבב בין שפות שונות.
מיתוס נפוץ הוא שניתן לייצג כל אות ביוניקוד בעזרת מספר בין 16 סיביות (או במילים אחרות, שיש פחות מ65536 אותיות ביוניקוד).
זה לא נכון, ולמעשה יש ביוניקוד גרסא 4.0 קרוב ל240,000 סימנים, מה שאומר שצריך לפחות 3 בתים כדי למספר את כל התווים ביוניקוד.
מחרוזת ביוניקוד היא בסך הכל סדרה של מספרים, כאשר כל מספר הוא המיקום של אות מסויימת בטבלא.
מקובל לסמן תו יוניקוד בסימן כמו U+0041, כאשר U+ אומר שזה יוניקוד והמספר שאחריו הוא קוד האות בבסיס הקסדצימלי.
לא במקרה, 128 התווים הראשונים ביוניקוד הם בדיוק אותם 128 התוים הראשונים באסקי וברוב קידודי הCode page.
המחרוזת hello ביוניקוד תכתב ככה:
U+0048 U+0065 U+006C U+006C U+006F
אם נשמור את זה, נקבל:
[code]
00 48 00 65 00 6C 00 6C 00 6F
[/code]
או
[code]
48 00 65 00 6C 00 6C 00 6F 00
[/code]
תלוי בשיטת בה אנחנו מקודדים ספרות בזכרון המחשב (Little endian או Big endian).
כדי להבחין בין שתי השיטות ישנה תוספת של התווים FE FF בתחילת מחרוזת יוניקוד (שתראה ככה או הפוך, לפי הEndianness של המכונה).
הסימון הזה נקרא Unicode Byte Order Mark, או בקיצור BOM – והוא גורם ללא מעט צרות לדפדפנים שכתובים רע.
UTF-8
באו האמריקאים ושאלו, מה אנחנו צריכים את האפסים האלו באמצע המחרוזת? הרי המחרוזת תופסת פי שתיים, והם גם מבלבלים תוכנות שמתייחסות ל0 בתור סימון לסוף המחרוזת (מקובל בC וC++).
וככה נולד UTF-8.
UTF-8 הוא שיטה לקידוד יוניקוד בקידוד בעל אורך משתנה.
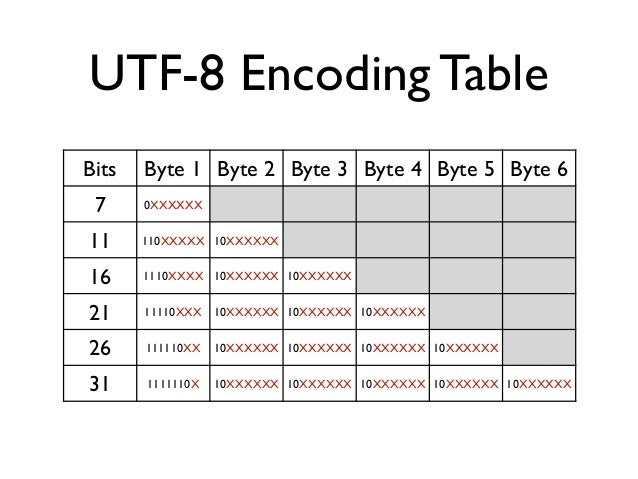
כשקוראים UTF-8, מסתכלים על התו הראשון ולפי הביטים הראשונים אפשר לדעת בדיוק על כמה בתים האות הבאה יושבת.
UTF-8 הפך לסטנדרט המקובל ביותר לקידוד מחרוזות יוניקוד.
PHP ויוניקוד
PHP התמיכה של PHP 4 ו5 ביוניקוד חלקית ביותר.
מחרוזות בPHP הן בעצם סדרה של בייטים ולא יותר ולמרות שתמיד אפשר להשתמש במחרוזת PHP כדי לשמור מחרוזות בקידודים שונים – רק במקרה שהPHP קומפל עם תמיכה בmb_string יהיו לנו פונקציות מיוחדות לטיפול במחרוזות מרובות בתים.
פתרון נוסף הוא להשתמש בספריה iconv, שמוסיפה לPHP יכולות המרה של קידודים, אבל היא לא מגיעה כברירת מחדל עם PHP ומי שרוצה תוכנה שתוכל לרוץ בקלות בכל מחשב ימנע ממנה.
בPHP 6 שמתבשל לאיטו צפויה תמיכה ביוניקוד, UTF-8 וכל זה, אבל זה עדיין לא שוחרר, ואם לשפוט לפי הקצב שלוקח לשוק לאמץ את PHP5 – אז PHP6 לא יהיה רלוונטי בשנים הקרובות למי שרוצה לשחרר תוכנה שתרוץ בכל מחשב.
מכיוון שהפונקציות הסטנדרטיות בPHP תומכות בעצם רק בקידוד שבו כל אות תופסת בייט אחד, הן יכולות ליצור בעיות מעניינות.
אם תקבלו מחרוזת שמקודדת בUTF-8, נניח "שלום", ותציגו אותה בדפדפן האורך שלה יהיה 4 אותיות. אם תשתמשו בפונקצית הPHP לחישוב אורך של מחרוזות, תקבלו שהאורך שלה הוא 8 תווים, כי כל אות מקודדת בשני בתים.
אם תנסו את אותו דבר על המחרוזת המעורבת "שלום SHALOM", תקבלו שהאורך הוא 8 + 1 + 6 = 15.
לעומת זאת, אם תשתמשו בmb_strlen תקבלו את האורך הנכון.
בעיה נוספת היא בעיה של חיתוך מחרוזות UTF-8.
אם נשתמש בפונקציה wordwrap לחיתוך מחרוזות UTF8, היא עלולה לחתוך אות בין שני הבתים שלה, ובעצם להעלים אותה. לא נעים.
הפתרון שלי היה לכתוב גרסא של wordwrap שעובדת על מחרוזות UTF-8.
אפשר להבין למה מפתחי PHP מתבלבלים כשהם מתעסקים עם מחרוזות בUTF-8.
המרות וקיבועים
למרות שרוב אתרי האינטרנט בימינו השכילו לעבור לUTF-8 לקידוד של מחרוזות, עדיין יש אתרים מסויימים שמשתמשים בקידודים מבוססי Code page. למשל – מנוע החיפוש של Walla מקודד לפעמים את מילות החיפוש בכתובת בקידוד עברית 1255 (עברית חלונות), ולפעמים בקידוד UTF-8. מאוד נחמד מצידם של המפתחים לפחות להעביר את הקידוד כחלק מהכתובת (e=hew לעברית 1255 וe=utf לutf8).
לא חסרות דוגמאות אחרות, בעיקר במנועי חיפוש מקומיים (yandex.ru, mail.ru שמשתמשים בקידוד קירילי 1251) ועוד.
מכיון שאני רוצה שמילות החיפוש יוצגו כמו שצריך בFireStats, צריך להמיר את הקידודים האלו לUTF-8.
הבעיה היא שכאמור – אין תמיכה מובטחת בiconv שמאפשר המרות כאלו, ולכן נאלצתי לכתוב בעצמי ספריית המרות קטנה מקידודי codepage כלשהם לקידוד UTF8. הספריה מסתמכת על טבלאות המרה שאפשר להשיג באתר הראשי של יוניקוד.
הרעיון של הספריה הוא להמיר באמצעות הטבלא את המחרוזת ליוניקוד, ואז לקודד אותה לUTF8.
וזו האגדה על אסקי יוניקוד וUTF-8.
קריאה נוספת
Joel on software במאמר מצויין על יוניקוד
מצגת על השרדות עם UTF-8
שאלות נפוצות על יוניקוד וUTF-8 בלינוקס ויוניקס
Unicode Introduction and Resources
עוד תקלת רשת מוזרה
בהמשך לפוסט האחרון על בעיות רשת מוזרות, הנה עוד אחת.
אפליקציית ג'אווה שכתבנו עובדת טוב לרוב האנשים, אבל משום מה "נתקעת" בהתחברות לחלק מהאנשים.
בבדיקה, נראה שהאפליקציה מתחברת לשרת, מקבלת תשובה ממנו, אבל לא קוראת את התוכן של התשובה.
בבדיקה מעמיקה יותר, רואים שהאפליקציה ניגשת לשדה הContent-Length של התשובה, ומקבלת משם 1-, מה שמרמז על זה שאין בתגובת הHTTP שדה של Content-Length.
בדיקה קטנה עם WireShark (לשעבר Ethereal) מראה את זה:
[code]
HTTP/1.1 200 OK
Date: Thu, 31 Jan 2008 13:21:24 GMT
Server: Microsoft-IIS/6.0
X-Powered-By: ASP.NET
X-AspNet-Version: 2.0.50727
Set-Cookie: ASP.NET_SessionId=j2hx2qvprzec3u55htsykh45; path=/; HttpOnly
Cache-Control: private
Content-Type: text/html
Content-Length: 20877
[/code]
(המשך התגובה נחתך מחוסר עניין).
אז נראה שהכל בסדר, יש Content-Length בתגובה.
ובכל זאת, אפליקציית הJava מקבלת 1-, ובדיבוג מעמיק אין רמז לContent-Length באובייקט שמייצג את תגובת הHTTP.
אז מה קורה פה?
הצעד הבא הוא לבדוק TCP נקי, בלי טובות של Java בפירסור התגובה.
תוכנית קטנה שמתחברת בTCP לשרת הHTTP, שולחת את הבקשה ומדפיסה את התוצאה מהשרת הפיקה את הפלט הזה:
[code]
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Date: Thu, 31 Jan 2008 13:21:24 GMT
Server: Microsoft-IIS/6.0
X-Powered-By: ASP.NET
X-AspNet-Version: 2.0.50727
Set-Cookie: ASP.NET_SessionId=j2hx2qvprzec3u55htsykh45; path=/; HttpOnly
Cache-Control: private
Content-Type: text/html
————–: —–
[/code]
יש פה כמה דברים שצריך לשים אליהם לב:
1. פתאום יש לנו בתשובה Transfer-Encoding: chunked.
2. מה זה איפה שקודם היה לנו Content-Length? ————–: —– ?? איזה וודו שחור פועל פה?
יש לציין שבזמן שאני מקבל את הנתונים האלו בתוכנית, אני מקבל נתונים זהים למה שראיתי קודם WireShark, כלומר – המחשב מקבל את הנתונים בצורה תקינה, אבל התוכנית מקבלת אותם אחרי טיפול.
כדי לנטרל אפשרות שJava התחלקה על השכל, ניסיתי (בעזרתו של חבר מהעבודה) להריץ תוכנית שעושה את אותו דבר בדיוק, רק שכתובה בC#.
לא במפתיע, התוצאה זהה: אין Content-Length, במקום זה יש שורת מינוסים.
מסקנה, Java לא אשמה הפעם.
אז מה נשאר?
מי משחק בתעבורת הרשת במחשב? אולי זה ווירוס, ואולי זה אנטי וירוס; בכל מקרה מדובר בתוכנה נאלחת.
לא במפתיע, האשם הוא הSymantec Client Firewall, שסורק בזמן אמת את תעבודת הHTTP, מחרבש אותה קלות, ומעביר את הזבל לתוכניות התמימות.
ברגע שנטרלתי את הסריקה שלו את פורט 80, הכל הסתדר.
יש לי משהו לומר למהנדסים של סימנטק:
אתם אינוולידים, מי נתן לכם את הזכות לשבש את התעבורה?
תסרקו, זה בסדר, אבל אין שום הצדקה שבעולם שהתוכניות שקוראות מהרשת יחשפו לשינויים שתרמתם.
אם הייתם עובדים אצלי הייתי משבש לכם את המשכורת.
אם הייתי כותב ווירוסים, הייתי משתמש במידע הזה בכיף כדי לזהות שהמחשב מריץ את הFirewall של סימנטק, שמשאיר עקבות כמו חזיר בחנות בורקסים.
ייעול הכנסת נתונים מנורמלים לבסיס הנתונים בFireStats
במסגרת מקצה אופטימיזציות לFireStats מימשתי מנגנון נוסף לקליטת כניסות.
המנגנון הרגיל בו כולם משתמשים היום בודק שהכניסה לא צריכה להיות מסוננת (כניסה של רובוט ידוע או IP מסונן למשל), ומכניס את הנתונים בצורה מנורמלת.
נירמול בסיס נתונים נועד למנוע כפילויות, מה שעוזר במניעת אנומליות ובחיסכון במקום. בFireStats הנרמול מתבטא בכך שכל כתובת נשמרת פעם אחת בטבלאת הURLים, כל UserAgent בטבלאת הUserAgents וכדומה. כאשר מכניסים את הנתון העיקרי של כל הכניסה, משתמשים במזהה של כל נתון מנורמל.
המשמעות של זה בזמן הכנסת הנתונים היא כזו:
הגיעה כניסה עם כתובת מסויימת, מפנה מסויים ודפדפן (UserAgent) מסויים. לכל אחד מהנתונים האלו מבצעים פחות או יותר את סדרת הפעולות הבאה:
הכנס לטבלא הרלוונטית עם INSERT IGNORE, מה שמונע שגיאה במקרה שהנתון כבר נמצא שם (הטבלאות מוגדרות לא לקבל רשומות כפולות).
בדוק מה המזהה של הנתון שהכנסנו (אם הוא נכנס, אז זה יהיה מזהה חדש, אם לא זה יהיה המזהה שנבחר בפעם הראשונה שהכנסנו את הנתון לטבלא).
לבסוף, הכנס שורה לטבלאת הכניסות תוך שימוש במזהים שמצאנו בצעדים הקודמים.
זה קצת יותר מורכב מזה כי גם צריך לזהות ולסנן כניסות מסויימות כאמור.
כל התהליך הוא איטי למדי.
יצרתי קובץ CSV עם 100,000 כניסות (מfirestats.cc) והשתמשתי בו למדידת הביצועים:
בשיטה של הכנסה מנורמלת של כל כניסה, הקצב מתחיל די לא רע עם 80 כניסות לשניה, אבל ככל שבסיס הנתונים מתמלא הוא יורד עד שמתייצב על 7-8 כניסות לשניה.
למרות שקצב כזה בהחלט מספיק לכל בלוג מצוי, הוא ממש לא מספק לאתרים רציניים יותר או לבלוגיות עתירות בלוגים.
כשהוספתי תמיכה בWPMU בFireStats 1.4, חזיתי (חודשים לפני שביצעתי את המדידות) שקצב הכניסות יכול להיות בעיה בבלוגיות והוספתי שיטה חדשה לקליטת נתונים.
במקום לקלוט את הנתונים בצורה מנורמלת, הנתונים נקלטים לטבלאת כניסות ממתינות בצורה לא מנורמלת עם INSERT DELAYED. המשמעות של הDELAYED היא שבסיס הנתונים מכניס את הנתונים בזמנו הפנוי, ולא מחזיק את הקורא עד שהנתון הוכנס ממש.
עדיין צריך לנרמל את הנתונים, ולכל כתבתי סקריפט PHP פשוט שעובר על הכניסות הלא מנורמלות בטבלא אחת אחת, ולכל אחת קורא לפונקציה הרגילה שקולטת נתונים ומנרמלת אותם, ולבסוף מוחק את הכניסה מטבלאת הכניסות הממתינות. (מנהל המערכת אחראי לדאוג שהסריפט ירוץ בפרקי זמן סבירים, למשל באמצעות cron).
אני שומע אתכם צועקים: כן, אבל זה יהיה איטי לפחות כמו קודם, אם לא יותר!
זה נכון, אבל לפחות זה מאפשר לתזמן את העיבוד של הכניסות לזמנים פחות עמוסים כמו הלילה.
חיסרון נוסף הוא שהמשתמשים כבר לא מקבלים את הנתונים בזמן אמת, אלא נתונים שנכונים נכון לזמן העיבוד האחרון של הכניסות בטבלאת הממתינים.
אחרי שמדדתי את הזמן שדרוש כדי להכניס 100,000 כניסות בשיטה הרגילה, כמובן שמדדתי את הזמן שדרוש בשיטה המעוכבת, שנועדה לשפר ביצועים.
מסתבר שבשיטה המעוכבת, FireStats קולט בסביבות ה1000 כניסות לשניה, אבל המילכוד הוא שהנתונים עדיין דורשים עיבוד כדי שיהיו שימושיים, והעיבוד יקר בדיוק כמו הטיפול הרגיל.
הצעד הבא הוא כמובן לשפר את הביצועים של העיבוד הנ"ל.
כבר מהרגע הראשון שכתבתי אותו, היה לי ברור שדרושה פה אופטימיזציה רצינית, והיה לי גם ברור שהיא תהיה מסובכת.
האופטימיזציה מתבססת על התובנה הבאה:
בתוך קבוצת כניסות שנקלטו בפרק זמן מסויים, יהיו חזרות רבות מאוד של כתובות, מפנים ודפדפנים.
מה אם במקום לטפל בהם אחד אחד, נטפל בהם בקבוצות? נניח 1000 כניסות בכל קבוצה?
במקום 1000 כתובות ו1000 מפנים, יהיו לנו משהו כמו 300 כתובות (שכוללים מפנים).
במקום משהו כמו 1000 דפדפנים יהיו לנו משהו כמו 50 או 100 דפדפנים.
עכשיו נצטרך להכניס את כל מה שחדש לבסיס הנתונים, לחלץ את המזהים שלהם, ולבסוף להכניס את הכניסות עצמן תוך שאנחנו משתמשים במזהים מקודם, רק שהפעם נכניס 1000 כניסות במכה במקום כניסה אחת.
המשמעות של זה היא בעצם לממש את הפונקציה שמכניסה כניסה בודדת – אבל לרוחב, כך שתהיה ברוחב של k כניסות (קבוע כלשהו).
המימוש של זה מורכב, ולמעשה לקח יותר מפי עשר שורות קוד מהמימוש התמים הקודם, אבל הביצועים סוכר:
מעיבוד של 8 כניסות בשניה, עליתי לעיבוד של 600 כניסות לשניה.
שיפור של פי 75!
עכשיו נשאר רק לבדוק נכונות.
אם אני לוקח חבילת כניסות נתונה, ומכניס אותה השיטה המיידית אך האיטית, או מכניס אותה בשיטה המעוכבת אך המהירה התוצאה בבסיס הנתונים צריכה להיות זהה.
לא דומה, זהה.
בהתחלה השתמשתי בmysqldump (תוכנית שמגיעה עם mysql כדי לגבות את בסיס הנתונים) כדי לשמור שני קבצים, מתוך כוונה להשוות אותם.
מסתבר שזה לא היה רעיון כל כך מוצלח, כי היא הפיקה שורות ארוכות מאוד מאוד, שגרמו לרוב תוכנות ההשוואה שניסיתי להתבלבל או פשוט להיות לא שימושיות.
הצלחתי לדעת שיש בעיות, אבל לא הצלחתי לזהות אותן.
אחרי חיפוש קצר מצאתי את phpsqldiff, תוכנת קוד פתוח שמאפשרת השוואה של טבלאות.
phpmysqldiff מסוגלת לומר בדיוק מה נוסף, מה ירד ומה השתנה בין שתי טבלאות, ובעזרתה מצאתי בדיוק מה שגוי ומשם הדרך לפתרון היא די קצרה.
אני שוקל ברצינות להפוך את שיטת קליטת הכניסות הזו לשיטה היחידה, אבל בשביל שזה יקרה היא תצטרך להיות יותר ידידותית למשתמש הפשוט:
למשל אם תהליך העיבוד יתבצע אוטומטית פעם ב10 דקות, ואולי אפילו בכל פעם שמנהל האתר בודק את הסטטיסטיקות.
מימוש כזה יגרום לעסק להיות שקוף, תוך הורדה משמעותית מהעומס על השרת.
זה עדיין לא הסוף של מקצה שיפור הביצועים: אני עדיין צריך לשפר את הביצועים של השאילתות, אבל זה בהחלט צעד חשוב בכיוון.
TorrentLeech2RSS חוזר
אחרי ניג'וסים ונדנודים, החברים בTorrentLeech בדקו את TorrentLeech2RSS ואישרו אותו לשימוש (כאילו, יכלתי לשחרר אותו בלי לומר להם, אבל אז הם היו משעים לי שוב את החשבון).
אז בקיצור, מי שרוצה להוריד, שיתכבד ויפנה לבלוג של הפרוייקט.
איך להוציא RSS מאתר שלא תומך בRSS?
לפני כמה שבועות הפיד RSS של TorrentLeech (להלן TL), ספק הסדרות העיקרי שלי, התחיל להחזיר 404 (דף לא נמצא).
אין פה שום דבר חדש, הפיד הזה אף פעם לא היה יציב במיוחד, לכן חיכיתי בסבלנות כשבוע, ואז התלוננתי בערוץ הIRC שהלינק של הפיד לא עובד.
גורם "רשמי" מסר לי שהפיד לא יחזור כי השתמשו בו לרעה.
ניסיתי לברר את פשר השימוש הפוחז, ואפילו הצעתי את עזרתי במציאת פיתרון, אך לשוא:
הילדון זב החוטם מסר שלא משנה מה אני אגיד או אעשה, הפיד לא חוזר.
הסברתי לו בדרכי נועם שאם המידע זמין באתר, אין שום הבדל כי אפשר להפוך אותו לפיד, אבל זה לא עזר.
אז החלטתי לעשות בדיוק את זה, וכך נולדה תוכנה חדשה – TorrentLeech2RSS.
בגדול, הרעיון הוא כזה:
שרת מקומי דוגם את TL, נניח פעם בחצי שעה.
השרת נכנס לTL, מזדהה עם שם המשתמש והסיסמא של המשתמש בTL, מוריד את דף הHTML שמכיל את רשימת הטורנטים בכל אחת מהקטגוריות הנבחרות, מפענח את הדף, ומחלץ ממנו את השם, הלינק, המזהה והתאריך של כל טורנט, ושומר אותם בזכרון.
במקום להשתמש בכתובת הRSS של TL (שאינה עימנו עוד), המשתמש מכניס כתובת של TorrentLeech2RSS, שמכין דף RSS ומחזיר אותו למבקש.
TorrentLeech2RSS גם משכתב את הלינקים בתוך הRSS שיעברו דרכו, כדי שיוכל להוסיף פרטי הזדהות שיעברו לשרת של TL ברגע שהמשתמש מנסה להוריד טורנט (אחרת הTracker של TL לא משתף פעולה עם המשתמש).
בחרתי לכתוב את tl2rss בשפת ג'אווה.
הצעד הראשון, וכנראה הכי קשה בתהליך, הוא להכנס תכנותית לאתר, התהליך מורכב יחסית וכולל כמה שלבים.
כדי להבין מה אני אמור לשלוח ומתי, השתמשתי בWireShark, וניטרתי את התעבורה שנוצרת כשאני מבצע לוגין בעזרת הדפדפן.
שימו לב במיוחד לאפשרת של Follow TCP Stream, שמציגה שיחת HTTP שלמה בצורה ברורה.
ברגע שהקוד הצליח להזדהות מול השרת, לבקש דף שמתאים לקטגוריה רלוונטית זה קל. אבל מה עושים עם הדף?
הדפים של TorrentLeech הם דוגמא לאיך נראה קוד HTML מבולגן ולא תקני, ערבוביה של תגיות HTML שכוללות תוכן, עיצוב ועימוד.
בקיצור, לא משהו שכיף במיוחד לחפוש בתוכו אחרי מידע.
הגישה הנאווית לבעיות כאלו היא שימוש בביטוי רגולרי, אבל זה לא יעבוד טוב בכל המקרים (מה קורה למשל אם יש HTML בתוך התאור של הטורנט?).
בחרתי ללכת לגישה טיפה יותר חזקה, והיא פירוק מלא של הHTML למבנה נתונים בזכרון, וניתוח של אותו מבנה.
ספרית ג'אווה שמאפשרת parsing כזה לHTML היא htmlparser הוותיקה.
אבל גם אם htmlparser מחזירה לנו עץ אובייקטים נוח, איך מוציאים ממנו את מה שמעניין? הוא ענק וסבוך ויותר מכל מסובך.
למזלי מצאתי בונה פילטרים ויזואלי עם htmlparser. אפשר להריץ אותו עם Java web start:
[code]
javaws http://htmlparser.sourceforge.net/samples/filterbuilder.jnlp
[/code]
או פשוט להריץ את הקוד ישירות (org.htmlparser.parserapplications.filterbuilder.FilterBuilder). עורך הפילטרים מאפשר ליצור פילטרים מורכבים בהדרגתיות תוך בדיקה מתמדת של התוצאה על דף הHTML שאתם רוצים לבדוק.
אזהרה: הוא לא הכי ידידותי בעולם, לוקח זמן להתרגל אליו – אבל הוא עובד.
לדוגמא, נניח שאנחנו רוצים לחלץ את רשימת השחקנים מהסרט ביוולף בIMDB.
קודם נכניס בשורה התחתונה את הURL, אחר כך נלחץ על fetch page, ואז נקבל את הHTML כעץ בחלק הימני.
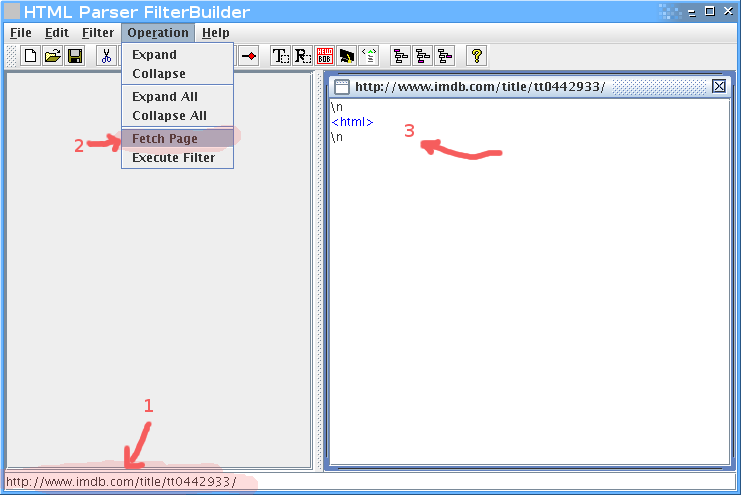
ברגע שיש לנו את הHTML, נתחיל לפלטר. חיפוש קצר אחרי שם של אחד השחקנים (Musician #2) מצא את הטבלא, ולמרבה הנוחות אפשר לראות שclass הCSS שלה הוא cast. זה מצויין, כי זה יאפשר לנו לדוג את הטבלא בקלות:
נוסיף פילטר של תכונות (attributes), נכניס בו את התכונה class עם הערך cast.
קליק ימני על הפילטר, execute filter, ונקבל חלון קטן בצד ימין עם התוצאות.
בינגו, יש לנו את הטבלה.
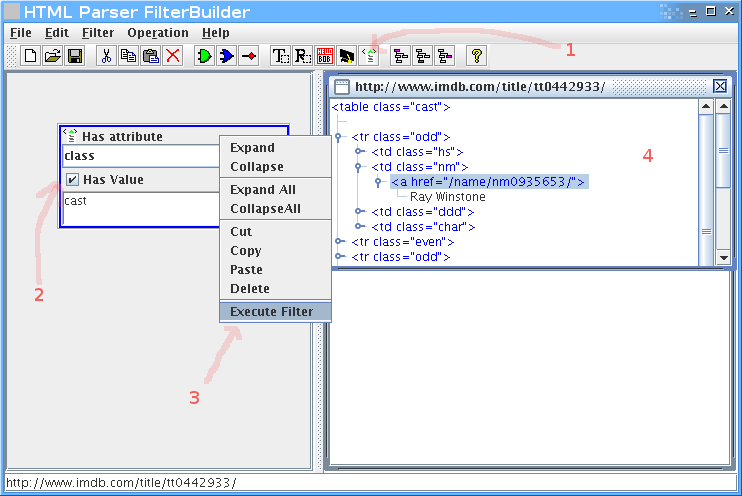
אבל אנחנו רוצים רק את רשימת השחקנים, אז צריך לעדן את הפילטר.
נוסיף שאנחנו רוצים רק טגים בשם TR, שיש להם הורה שהוא טבלא עם תכונה של class שערכו cast:
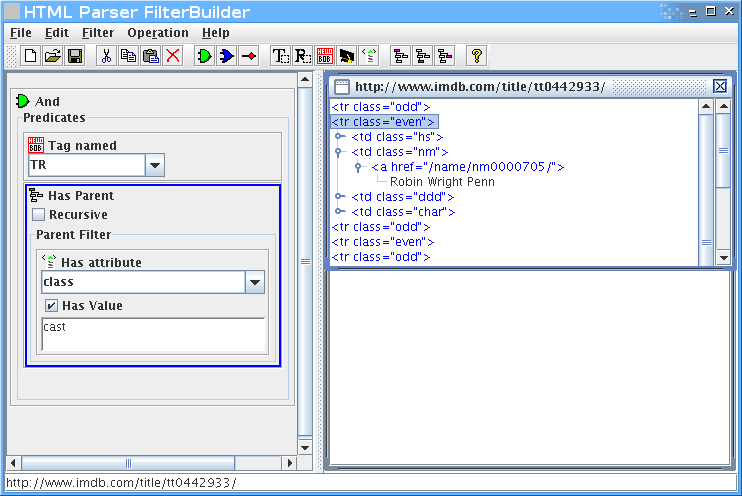
אפשר להמשיך, אבל הרעיון – אני מקווה – ברור.
ברגע שאנחנו מרוצים מהפילטר שיצרנו, אפשר לשמור אותו.
זה מה שיוצא (גרסא מקוצרת):
[code lang="java"]
// Generated by FilterBuilder. http://htmlparser.org
// [aced0005737200206f…….17374]
import org.htmlparser.*;
import org.htmlparser.filters.*;
import org.htmlparser.beans.*;
import org.htmlparser.util.*;
public class imdb
{
public static void main (String args[])
{
TagNameFilter filter0 = new TagNameFilter ();
filter0.setName ("TR");
HasAttributeFilter filter1 = new HasAttributeFilter ();
filter1.setAttributeName ("class");
filter1.setAttributeValue ("cast");
HasParentFilter filter2 = new HasParentFilter ();
filter2.setRecursive (false);
filter2.setParentFilter (filter1);
NodeFilter[] array0 = new NodeFilter[2];
array0[0] = filter0;
array0[1] = filter2;
AndFilter filter3 = new AndFilter ();
filter3.setPredicates (array0);
NodeFilter[] array1 = new NodeFilter[1];
array1[0] = filter3;
FilterBean bean = new FilterBean ();
bean.setFilters (array1);
if (0 != args.length)
{
bean.setURL (args[0]);
System.out.println (bean.getNodes ().toHtml ());
}
else
System.out.println ("Usage: java -classpath .:htmlparser.jar:htmllexer.jar imdb
}
}
[/code]
בראש הקובץ יש קידוד של הפילטר, מה שמאפשר לנו לטעון את הקובץ ולהמשיך לעבוד עליו מאותה נקודה.
כדי לקמפל את זה צריך כמובן את htmlfilter.jar בclasspath.
טוב, אז נניח שכתבנו פילטר מתאים, וגיבינו אותו בקצת קוד שמוציא את הנתונים לרשימה נוחה.
איך הופכים את זה לRSS?
בקלות, בעזרת ספרית ג'אווה בשם Rome.
השימוש ברומא פשוט מאוד, הנה דוגמא:
[code lang="java"]
public String getListRSS() throws FeedException
{
SyndFeed feed = new SyndFeedImpl();
feed.setFeedType("rss_2.0");
feed.setTitle("My RSS!");
feed.setLink("http://firefang.net/blog/768");
feed.setDescription("A feed for you!");
List entries = new ArrayList();
feed.setEntries(entries);
Vector v = new Vector();
v.add("item1");
v.add("item2");
v.add("item3");
for (int i = 0; i < v.size(); i++)
{
SyndEntry entry = new SyndEntryImpl();
entry.setTitle((String) v.elementAt(i));
entry.setLink("http:://imdb.com/");
entries.add(entry);
}
SyndFeedOutput output = new SyndFeedOutput();
return output.outputString(feed);
}
[/code]
שמפיקה את הRSS הזה:
[code lang="xml"]
[/code]
אז עכשיו שאנחנו יודעים לקחת דף HTML ולהוציא ממנו טקסט של RSS, נשאר רק לאפשר לקורא RSS רגילים לגשת אליו.
הדרך הטבעית תהיה להריץ שרת ווב קטן, שיגיש את קובץ הRSS למי שמבקש.
בחרתי להשתמש בJetty, שהוא שרת ווב קטן וגמיש בג'אווה, שמאפשר גם שילוב פשוט וקל בתוך אפליקציות אחרות.
לא להבהל מגודל ההורדה שלו, כדי להשתמש בו בתוך האפליקציה שלכם מספיק לקחת שלושה Jarים בגודל כולל של כ700K.
ככה משלבים את Jetty בתוך הישום שלכם, שימו לב כמה שזה פשוט.
[code lang="java"]
Handler handler=new AbstractHandler()
{
public void handle(String target, HttpServletRequest request, HttpServletResponse response, int dispatch)
throws IOException, ServletException
{
response.setContentType("text/html");
response.setStatus(HttpServletResponse.SC_OK);
response.getWriter().println("
Hello
");
((Request)request).setHandled(true);
}
}
Server server = new Server(8080);
server.setHandler(handler);
server.start();
[/code]
כדי לגשת אליו, נפתח את הדפדפן על http://localhost:8080 במקרה שלנו.
עכשיו רק נשאר לקשור את החוטים ביחד.
פתחתי בלוג קטן לפרוייקט, וחיש מהר החשבון שלי בTorrentLeech הושעה. כשביררתי מה הסיפור נאמר לי שהם חוששים שאני אגנוב למשתמשים סיסמאות.
הצעתי להם לבדוק את הקוד, ושעד אז אני אוריד את הלינק, וכך עשיתי, והחשבון שלי שוחזר.
בינתיים הם עדיין לא חזרו אלי, והסבלנות קצת פקעה.
מי שרוצה להוריד את הקוד יכול להוריד אותו מפה עם לקוח Subversion.
מי שרוצה להוריד את הבינארי מוזמן להוריד אותו מפה.
יש הוראות שימוש בתוך קובץ הREADME.
tl2rss משוחרר תחת רשיון GPL-3.0.
ספרית מפות חדשה לפיתוח אפליקציות web
לאחר חודשים של עבודה מפרכת שחררתי היום את ספרית המפות מבוססת ה-Google Web Toolkit שלי. הספריה מאפשרת פיתוח אפליקציות web עם מפות בשפת Java (החביבה עלי וכן על עמרי עד מאוד), כשם ש-Google Maps API מאפשר זאת למפתחי JavaScript.
לאחר נסיוני המר עם ה-GPL פרסמתי את ספרית המפות תחת ה-CC BY-NC-SA.
יום הולדת שמח, עמרי, ותהנה מהאוגרים!
למה אני שונא סלולארים של מוטורולה
מפתחי ג'אווה שמפתחים למכשירים סלולאריים הם עם די מסכן, יש בעיות שונות ומשונות במכשירים מסויימים, ואם אתם רוצים שהישום שלכם יעבוד בכל המכשירים צפויה לכם דרך קשה ומייגעת.
ללא ספק, החברה שמייצרת את המכשירים השנואים ביותר עלי אישית היא מוטורולה.
למרות שהמכשירים החדשים של מוטורולה (RAZR2-V9 שמריץ לינוקס, V6 ואפילו V3) הם מכשירים חזקים, עתירי זכרון ועם תקשורת נתונים מהירה מאוד, הם עדיין שנואים במיוחד.
איך זה?
הבעיה עם מוטורולה, היא שלמרות שהם מייצרים מכשירים עם חומרה מצויינת, התוכנה שלהם היא לא פחות מפיגוע רב נפגעים.
הבעיות מתחילות בממשק מעצבן ולא אינטואיטיבי (נסו לקבוע דף בית לדפדפן, או להעלות אפליקציית ג'אווה דרך הכבל USB), וממשיכות במגוון באגים במכשירים.
HTTP 100
HTTP 1.1 תומך בקוד תגובה 100, שאומר לקליינט להמשיך לקרוא הלאה. השרת יכול לשלוח את זה אם הוא רוצה אחרי שהוא קרא את הכותרות של הבקשה, והלקוח אמור להמשיך את הבקשה אוטומטית בצורה שקופה למתכנת.
הבעיה היא שמוטורולה לא עובדים לפי הפרוטוקול, ומחזירים לאפליקציה את הקוד 100, ומשם התגובה האמיתית של השרת כבר אבודה.
יש פתרון שמצליח לעקוף את הבעיה הזו, והוא האק בקנה מידה בין לאומי. לא משהו שהייתם מכניסים לאפליקציה (ולשרת) אם לא היו מאיימים עליכם שיחליפו את המכשיר האישי שלכם למוטורולה.
כתיבה של קבצים בRAZR2
RAZR2 הוא המכשיר החדש ביותר של מוטורולה, והוא מריץ לינוקס. לכאורה, הזדמנות פז למוטורולה להוציא תוכנה פחות מסריחה.
איכשהו, מוטורולה הצליחו ליצור באג בכתיבה של קבצים בשימוש בFileConnection.
הבאג ממש ביזארי, וגרם לכך שלפעמים קבצים שתכתבו לא יכתבו כמו שצריך למערכת הקבצים.
הבאג מופיע בעיקר כשוכתבים "הרבה" נתונים במכה, למשל:
[code lang="java"]
byte buf[] = new byte[20000]; // create buffer
for (int i = 0; i < buf.length; i++) buf[i] = (byte) i; // populate with some crap
FileConnection conn = (FileConnection) Connector.open("file:///..."); // open file connection
OutputStream out = conn.openOutputStream(); // open output stream
out.write(buf); // write buffer to file
// cleanup
out.close();
conn.close();
conn = (FileConnection) Connector.open("file:///..."); // open file connection again
InputStream in = conn.openInputStream();
// read, you are in for a surprise
[/code]
פתרון שעובד לבעיה המוזרה הזו הוא לכתוב את הקובץ בכמה חתיכות יותר קטנות, למשל:
[code lang="java"]
private void writeChunked(byte[] buffer, OutputStream out) throws IOException
{
final int MAX = 4096;
int offset = 0;
while (offset < buffer.length)
{
int chunkSize = (buffer.length - offset > MAX ? MAX : buffer.length – offset);
out.write(buffer, offset, chunkSize);
offset += chunkSize;
out.flush();
}
}
[/code]
ממשק לעיון בקבצים
מוטורולה לא מספקים ממשק לעיון במערכת הקבצים על הפלאפון, רק משהו מוגבל שמאפשר גישה לתמונות ומדיה בלבד.
זה מראה שהם מפחדים מהמשתמשים שלהם, ולא סומכים על מערכת ההפעלה שלהם שתעמוד בפני משתמש חקרן.
אם במכשירים מהדור הקודם אפשר איכשהו לעיין בקבצים באמצעות MIDWay הזוועתית (תוכנה לניהול של מכשירי מוטורולה), בגרסאות החדשות (לינוקס) זה לא עובד עדיין.
הגבלות משאבים מגוחכות
במוטורולות למיניהן, אין אפשרות לפתוח יותר מארבעה חיבורי רשת בו זמנית. זה אולי נשמע הרבה, אבל זה לא.
הרבה ישומים נאלצים להתעקם בגלל המגבלה הזו.
בעיה נוספת היא שאי אפשרת לפתוח יותר מ14 קבצי קול בו זמנית (ליתר דיוק, 14 Players).
אפליקציות שמנגנות אפקטים קוליים טוענות בדרך כלל את הצלילים מראש כדי לנגן אותם מהר בעת הצורך. במוטורולה החליטו ש14 זה מספיק, מה שמכריח אפליקציות עתירות סאונד לקפוץ דרך חישוקי אש נוספים.
חוסר יציבות
זה אולי ישמע כמו התבכיינות, במיוחד למפתחי סלולארי שרגילים לקריסות (BREW, Symbian), אבל קל מאוד לגרום למכשירי מוטורולה לקרוס.
מספיק לפתוח ולא לסגור יותר מדי קבצים. במקום לקבל איזו שגיאה סבירה, המכשיר זורק במקרה הטוב "IOException : native error" ובמקרה הפחות טוב פשוט נתקע לחלוטין.
תמיכה במקשים
שינאה מיוחדת גורמת התמיכה במקשים במכשירי מוטורולה.
הקודים של המקשים שונים מהקודים של יצרני סלולאר אחרים, ואם על זה אני מוכן לסלוח, אני הרבה פחות סלחן כשמדובר בהבדלים בקודי הלחיצה בין מכשירי מוטורולה שונים, כשלפעמים ההבדל היחיד בינהם הוא מאיזה ספק נרכש המכשיר.
זה בהחלט גורם לצער ויגון לא מבוטל למפתחי משחקים.
בעית מקשים נוספת היא התמיכה הצולעת במצב שהמשתמש לוחץ על שני כפתורים בו זמנית.
במכשירים מסויימים, למשל V9m, האפליקציה מקבלת שני ארועי "מקש נלחץ" וארוע יחיד של "מקש שוחרר", במכשירים אחרים בכלל לא מקבלים ארועים על הכפתור השני שנלחץ.
התממשקות למחשב
מוטורולה עדיין לא הבינו שחיבור בממשק של מודם (פקודות AT) פס מהעולם, וישום הניהול שלהם – MIDWay (המשוקץ) מתחבר למכשיר ממש כאילו הוא מודם. מי שזוכר את המחלות של מודמים (מה הערוץ הCOM? מה הBaud rate? שיט, העכבר לא זז, שיט הCOM נתקע וצריך לאתחל את המחשב) ירגיש כמו בבית.
ההתקנה של ישומי ג'אווה היא ממש מציקה:
כדי להתקין, צריך לחפור בתפריטי המכשיר למצוא אפשרות נסתרת שמעבירה את המכשיר למצב טעינת ג'אווה, להפעיל אותה, ורק אז לחבר את הכבר נתונים (אם הוא היה מחובר כבר, צריך לנתק אותו! Serenity now!).
דבר מעצבן נוסף הוא שברגע שמחברים את המכשיר למחשב עם הכבל, ישום הג'אווה הפעיל – אם יש כזה, מושהה מיד ואי אפשר להריץ אותו.
למה? כי מוטורולה עושים כל מה שהם יכולים כדי לעלות למפתח הנואש על העצבים.
בלוטות'
התמיכה בבלוטות' במכשירי מוטורולה חלקית ביותר, ולא מאפשרת פעולות טרויאליות כמו התקנה של תוכנת ג'אווה דרך בלוטות', או עיון בקבצים שעל המכשיר.
כמיטב המסורת, לקראת שנת 2008, מוטורולה עדיין חוסמים את המשתמשים ואת המפתחים מכל דבר שמזכיר נוחות עבודה מול מכשירים אחרים.
יש לציין שיצא לי לעבוד עם מכשירי מוטורולה לראשונה לפני ארבע או חמש שנים, וכבר אז שנאתי אותם פחות או יותר מאותן סיבות.
מוטורולה הוציאו כמות מפחידה של מכשירים מאז, אבל לא תיקנו תקלות שמישות בסיסיות בשיטת העבודה עם המכשירים.
סיכום
אין ספק בליבי שמוטורולה מנסים, אבל משום מה הם לא מצליחים.
אולי המפתחים שלהם לא יוצלחים, ואולי יש בעיה בתרבות הארגונית שלהם שמונעת מאנשים לזהות או להגיב לחרא שהם מייצרים.
בכל מקרה, התוצאה זהה.
אני שונא את מוטורולה.
Silverlight
מייקרוסופט שחררו גרסא ראשונה שאינה גרסאת בטא של Silverlight, הפלטפורמה המתחרה של מייקרוסופט לפלאש של אדובי.
כמו בפלאש, Silverlight תומך בגרפיקה חלקה (Anti aliased), ובהזרמה של וידאו.
כמו בפלאש, קליק ימני על רכיב Silverlight פותח תפריט מיותר, וכמו בפלאש – אין אפשרות למפתחים בSilverlight לעקוף את התפריט הזה ולהשתמש בקליק הימני בשביל דברים אחרים, תפריטים קופצים למשל.
למה?
אני מנחש שמייקרוסופט לא רצו שאנשים יראו את הSilverlight היפה שלהם, ויחשבו שזה פלאש.
אם מקרומדיה/אדובי יכולים להשתין בקשת על המשתמשים שלהם, גם מייקרוסופט יכולים.
אחת הסיבות שאני לא רוצה ללמוד פלאש, היא שאני לא יכול לסמוך על חברה שהחליטה שהחליטה להלאים את הקליק הימני כדי להציג תפריט הגדרות אידיוטי שתכתוב APIים שלא יגרמו לי לרצות להקיא.
זו בדיוק הסיבה שאני לא אתקרב לSilverlight (גם אחרי שתצא גרסאת הלינוקס שלו) עד שמייקרוסופט לא יתעשתו ויחזירו את הקליק הימני לעם.
שנה לFireStats

ככה בלי שאני אשים לב, FireStats חגגה יום הולדת שנה בשבוע שעבר.
הנה ההכרזה על על השחרור של הגרסא הראשונה, 0.9-בטא.
אז מה היה בשנה הזו?
403,000 דפים נצפו באתר של FireStats, על ידי 96,700 מבקרים.
סך הכל כ31,000 הורדות שמתפרשות על פני כ30 גרסאות ששוחררו.
הגרסא שהורדה הכי הרבה פעמים היתה 1.1.5, עם כ7800 הורדות.
תמיכה ב16 שפות.
תמיכה ב8 פלטפורמות, וכן באתרי PHP וC# כלליים.
407 פניות באתר (דיווחי באגים, בקשות עזרה ובקשות שיפור), מתוכן 61 פתוחות כרגע, רובן המכריע בקשות שיפור.
1180 גרסאות במערכת ניהול הגרסאות בקוד (Subversion).
ושיא של לפחות 2518 אנשים שפתחו את FireStats ביום אחד, שנקבע אתמול (אני יודע לפי מספר הבקשות לבדיקת גרסא חדשה).
נקוה שהשנה השניה תהיה טובה לפחות כמו הראשונה :).