סוני הכריזה על תקן חדש ופרטי לתקשורת אלחוטית בשם TransferJet.
בניגוד לWireless USB שמגיע למהירות של 480 מגה ביט לשניה למרחק של עד שלושה מטרים, ו110 מגה ביט למרחק של עד עשרה מטרים, הסטנדרט של סוני מגיע למהירות של 560 מגה ביט לשניה ממרחק של שלושה סנטימטרים.
קראתם טוב.
הרעיון הוא ליצור פרוטוקול פשוט שישמש להעברת נתונים אוטומטית בין מכשירים, נניח – שימו את המצלמה ליד הטלוויזיה, והיא כבר תעביר לטלוויזיה לבד את התמונות.
רוצים לסנכרן את נגן הMP3? שימו אותו ליד המחשב והמחשב כבר יעביר אליו לבד את הנתונים.
נשמע טוב, עד שחושבים על זה טיפה יותר:
הוא יעביר את הכל? מה עם שירים שכבר נמצאים על המכשיר?
ומה אם אני דווקא רוצה להעביר בכיוון השני?
אין ספק שסוני, שאחראית להצלחות מסחררות כמו המינידיסק, פורמט הדחיסה Atrac (שסוני הפסיקה את התמיכה בו), Memory stick – סטנדרט לאיכסון, דומה לדיסק-און-קי, רק שאף אחד לא משתמש בו), sdds (סטנדרט קולנועי לצליל דינמי, שסוני כבר לא תומכת בו) ועוד – מבקשת לשחזר את הישגי העבר ולפתח תקן מיותר חדש.
אחרי ניג'וסים ונדנודים, החברים בTorrentLeech בדקו את TorrentLeech2RSS ואישרו אותו לשימוש (כאילו, יכלתי לשחרר אותו בלי לומר להם, אבל אז הם היו משעים לי שוב את החשבון).
אז בקיצור, מי שרוצה להוריד, שיתכבד ויפנה לבלוג של הפרוייקט.
בשעה טובה, התחילה חקירה נגד Comcast על ההתערבות הנבזית בתעבורת הרשת של המשתמשים שלה.
Comcast נתפסה מזייפת חבילות RST, טכניקה ערמומית ונכלולית להגביל תעבורת אינטרנט (דמיינו שאתם מתקשרים למישהו בטלפון, הוא עונה ואומר שהוא לא יכול לדבר כרגע, רק שבעצם זה לא הוא ענה, אלא ספק הטלפוניה שלהם שהגדיל ראש בכוונה להוריד מהעומס על רשת הטלפונים).
כתבתי כבר שכדאי מאוד שהשוק יראה לComcast שהטריקים האלו לא מקובלים ויכאיב לה איפה שכואב, אחת תתחיל מגפה של ספקיות שחוסמות תעבורת נתונים "לא לגיטימית" לאור יום.
במסגרת השופינג ספרי פה בסיאטל, רכשתי iPod touch עם 8GB זכרון.
המחיר בארצות הברית יותר זול משמעותית מאשר בארץ, גרסאת ה8 ג'יגה עולה 299$ וגרסאת ה16 ג'יגה עולה 399$.
חוץ מניגון מוסיקה, הוא גם מאפשר גלישה דרך Wifi.
הממשק דומה לזה של הiPhone:
מסך מגע ענק, שמזהה כמה נקודות לחיצה (אפשר למשל לעשות זום אין בדפדפן על ידי "צביטה").
הדפדפן הוא ספארי די סטנדרטי, שגולש יפה מאוד (אפילו פיירסטטס עובד שם!), וכמובן שיש מקלדת מגע.
חסר פונט לעברית בדפדפן, אבל נתקלתי כבר בפתרונות לבעיה הזו לiPhone ואני די בטוח שהם יעבדו גם על הTouch.
איכות הסאונד טובה, והווליום גבוה מספיק כדי שלא תרצו לשמוע מוזיקה בווליום הכי גבוה.
לא בדקתי עדיין, אבל הסוללה אמורה להספיק ל22 שעות מוסיקה לפי אפל, ול17 שעות לפי ביקורות באינטרנט. בכל מקרה די והותר אפילו לטיסה טרנס אטלנטית (אהם).
הiPod touch מאוד מזכיר את הiPhone, בכמה הבדלים:
* הוא לא טלפון, אז אין התחייבות או התקשרות עם ספק סלולרי (יתרון ענק).
* אין לו Bluetooth, די חבל.
* המכשיר יותר דק.
* אין לו מיקרופון פנימי.
נראה שאפל עשו די הרבה כדי למנוע מהטאץ' להפוך למכשיר טלפון, אבל לא מספיק:
מסתבר שהפינים של הקלט הקולי פעילים בחיבור התחתון של הטאץ', ואנשים כבר עמלים על נסיון להוציא שיחת VOIP דרכו.
יש חרושת שמועות רצינית שהטאץ' כולל צ'יפ של בלוטות', אבל הוא מכובה, בינתיים לא מצאתי הוכחה או הפרכה לטענה הזו.
סך הכל, הטאץ' הוא כמעט מחשב לכל דבר. צדיקים פרצו אותו כדי לאפשר התקנה חופשית של תוכנות עליו
ועושה רושם שהוא מריץ את מה שהiPhone מריץ, מה שנותן מבחר די רציני של תוכנות ומשחקים.
דבר מעניין הוא שהטאץ' כולל חיישני תנועה כדי לזהות סיבוב של המכשיר (כדי להתאים את מה שמוצג על המסך לזווית ההחזקה), מה שאפשר כמה משחקים מאוד נחמדים שמתבססים על הטיה של הטאץ בזוויות שונות.
לסיכום, הטאץ' ממש יפהפה ועושה רושם של מכשיר מאוד ידידותי להאקרים, למרות שאני לא חושב שזו היתה הכוונה של אפל.
לגבי לינוקס, מכיוון שאין לי פה (חוץ מאיזה דביאן קטן בVirtual box – אבל זה לא הדבר האמיתי), עדיין לא סינכרנתי את הטאץ' על לינוקס.
אבל אנשים כבר עשו את זה, עוד על זה בהמשך.
עכשיו אני צריך למצוא מה לעשות עם הסנסה שקניתי לפני פחות משלושה חודשים.
מישהו רוצה לקנות Sansa E280 עם 8 ג'יגה זכרון?
הנגן במצב מצויין, עם רוקבוקס מותקן (אפשר בקלות להחזיר את הקושחה המקורית), ואני אזרוק פנימה גם נרתיק זרוע.
מי שרוצה לקנות שישלח לי אימייל.
כבר בטיול האחרון להולנד וגרמניה חשבתי לקנות Nintendo Wii, אבל פשוט אי אפשר היה למצוא Wii באף חנות.
חצי שנה אחר כך, בחג המולד, המצב לא יותר טוב: למעשה, הוא יותר גרוע:
מי שרוצה לקנות Wii בחנות, יכול להרשם ולקבל אותו ב21 בינואר, שזה כמה שבועות אחרי שאני חוזר.
למזלי, השותף שלי לנסיעה – יניב – היה ממש לחוץ על Wii, והסכים לחפש בנרות בתנאי שאני אקנה אם הוא מוצא.
הוא גילה כמה אתרים שמתמחים בחיפושיי Wii, כשהמעניין בהם הוא wii.FindNearBy.net שמאפשר חיפוש עם אינטגרציה לגוגל מפות ולכמה רשתות מאוד משמעותיות (Ebay, אמזון, וולמארט, Target וכו').
במילים אחרות:
תמצא לי כל מי שמוכר Wii ברדיוס של 25 מיילים (או כל מרחק אחר) ממני.
מצאנו ככה Wii ב315$ בEbay, ובאותו יום נפגשתי עם המוכר בקניון South center שנמצא במרחק חמש דקות נסיעה מהמלון, והכסף החליף ידיים, וגם הWii. על הדרך קניתי בקניון את Super mario galaxy לWii, כדי שיהיה מה לשחק.
הWii ממש חדש, והגיע עם הניילונים בקופסא. מסתבר שהילדים שם רצו נורא PS3 לקריסמס, ופניהם נפלו למראה הWii.
החוויה של קניה באיביי בארצות הברית שונה לגמרי מאשר בארץ, ולו בגלל שקל מאוד למצוא מישהו שמוכר מה שאתם רוצים בקרבתכם. ההבדל משמעותי מאוד: במקום לשלם מחיר מופקע כדי לקבל את זה בדואר איטי לארץ, נפגשים באיזה מקום ואוספים את הרכש במהירות.
למרבה הצער, הטלוויזיה במלון מצו'קמקת למדי ואין לה חיבורים RCA מתאימים, אז לא יצא לי לבדוק את הרכש החדש, אבל הזמן לזה יגיע :).
הWii שלי צורך במתח ב110 וולט, ואני עדיין מחפש פתרון לזה:
או שאני אקנה פה ספק כוח שמתאים גם ל220 וולט (קצת קשה למצוא פה), או שאני אקנה בארץ ממיר 220 -> 110 וולט.
בכל מקרה, אני לא מודאג – הבעיה הזו פתירה.
חיים טוב האמריקאים.
מי שרוצה למצוא סרט פשוט כותב בגוגל את שם העיר וCinema, למשל Renton cinema, ומקבל רשימת בתי קולנוע, ומה כל אחד מהם מציג היום.
מתי אצלנו?
בחור חכם בשם ג'וני לי עושה כמה דברים מדהימים עם השלט של נינטנדו Wii, הידוע גם כWiimote.
ההברקה האחרונה, מעקב אחרי תנועות ראש באמצעות הWiimote, מה שמאפשר התאמה של מודלים תלת מימדיים לנקודת המבט של המתבונן, או במילים אחרות תלת מימד אמיתי במסך המחשב שלכם.
שווה להכנס לאתר שלו לראות את איך הוא עושה מסך מגע ומעקב אחרי אצבעות (באוויר) באמצעות הWiimote.
קניתי שלט כזה, ואני מתכוון להשתעשע בו (40$, כמה עולה בארץ? :).
לפני כמה שבועות הפיד RSS של TorrentLeech (להלן TL), ספק הסדרות העיקרי שלי, התחיל להחזיר 404 (דף לא נמצא).
אין פה שום דבר חדש, הפיד הזה אף פעם לא היה יציב במיוחד, לכן חיכיתי בסבלנות כשבוע, ואז התלוננתי בערוץ הIRC שהלינק של הפיד לא עובד.
גורם "רשמי" מסר לי שהפיד לא יחזור כי השתמשו בו לרעה.
ניסיתי לברר את פשר השימוש הפוחז, ואפילו הצעתי את עזרתי במציאת פיתרון, אך לשוא:
הילדון זב החוטם מסר שלא משנה מה אני אגיד או אעשה, הפיד לא חוזר.
הסברתי לו בדרכי נועם שאם המידע זמין באתר, אין שום הבדל כי אפשר להפוך אותו לפיד, אבל זה לא עזר.
אז החלטתי לעשות בדיוק את זה, וכך נולדה תוכנה חדשה – TorrentLeech2RSS.
בגדול, הרעיון הוא כזה:
שרת מקומי דוגם את TL, נניח פעם בחצי שעה.
השרת נכנס לTL, מזדהה עם שם המשתמש והסיסמא של המשתמש בTL, מוריד את דף הHTML שמכיל את רשימת הטורנטים בכל אחת מהקטגוריות הנבחרות, מפענח את הדף, ומחלץ ממנו את השם, הלינק, המזהה והתאריך של כל טורנט, ושומר אותם בזכרון.
במקום להשתמש בכתובת הRSS של TL (שאינה עימנו עוד), המשתמש מכניס כתובת של TorrentLeech2RSS, שמכין דף RSS ומחזיר אותו למבקש.
TorrentLeech2RSS גם משכתב את הלינקים בתוך הRSS שיעברו דרכו, כדי שיוכל להוסיף פרטי הזדהות שיעברו לשרת של TL ברגע שהמשתמש מנסה להוריד טורנט (אחרת הTracker של TL לא משתף פעולה עם המשתמש).
בחרתי לכתוב את tl2rss בשפת ג'אווה.
הצעד הראשון, וכנראה הכי קשה בתהליך, הוא להכנס תכנותית לאתר, התהליך מורכב יחסית וכולל כמה שלבים.
כדי להבין מה אני אמור לשלוח ומתי, השתמשתי בWireShark, וניטרתי את התעבורה שנוצרת כשאני מבצע לוגין בעזרת הדפדפן.
שימו לב במיוחד לאפשרת של Follow TCP Stream, שמציגה שיחת HTTP שלמה בצורה ברורה.
ברגע שהקוד הצליח להזדהות מול השרת, לבקש דף שמתאים לקטגוריה רלוונטית זה קל. אבל מה עושים עם הדף?
הדפים של TorrentLeech הם דוגמא לאיך נראה קוד HTML מבולגן ולא תקני, ערבוביה של תגיות HTML שכוללות תוכן, עיצוב ועימוד.
בקיצור, לא משהו שכיף במיוחד לחפוש בתוכו אחרי מידע.
הגישה הנאווית לבעיות כאלו היא שימוש בביטוי רגולרי, אבל זה לא יעבוד טוב בכל המקרים (מה קורה למשל אם יש HTML בתוך התאור של הטורנט?).
בחרתי ללכת לגישה טיפה יותר חזקה, והיא פירוק מלא של הHTML למבנה נתונים בזכרון, וניתוח של אותו מבנה.
ספרית ג'אווה שמאפשרת parsing כזה לHTML היא htmlparser הוותיקה.
אבל גם אם htmlparser מחזירה לנו עץ אובייקטים נוח, איך מוציאים ממנו את מה שמעניין? הוא ענק וסבוך ויותר מכל מסובך.
למזלי מצאתי בונה פילטרים ויזואלי עם htmlparser. אפשר להריץ אותו עם Java web start:
[code]
javaws http://htmlparser.sourceforge.net/samples/filterbuilder.jnlp
[/code]
או פשוט להריץ את הקוד ישירות (org.htmlparser.parserapplications.filterbuilder.FilterBuilder). עורך הפילטרים מאפשר ליצור פילטרים מורכבים בהדרגתיות תוך בדיקה מתמדת של התוצאה על דף הHTML שאתם רוצים לבדוק.
אזהרה: הוא לא הכי ידידותי בעולם, לוקח זמן להתרגל אליו – אבל הוא עובד.
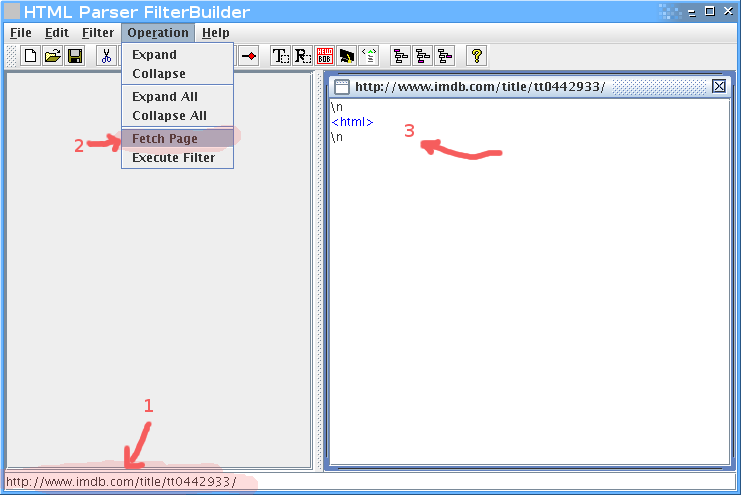
לדוגמא, נניח שאנחנו רוצים לחלץ את רשימת השחקנים מהסרט ביוולף בIMDB.
קודם נכניס בשורה התחתונה את הURL, אחר כך נלחץ על fetch page, ואז נקבל את הHTML כעץ בחלק הימני.
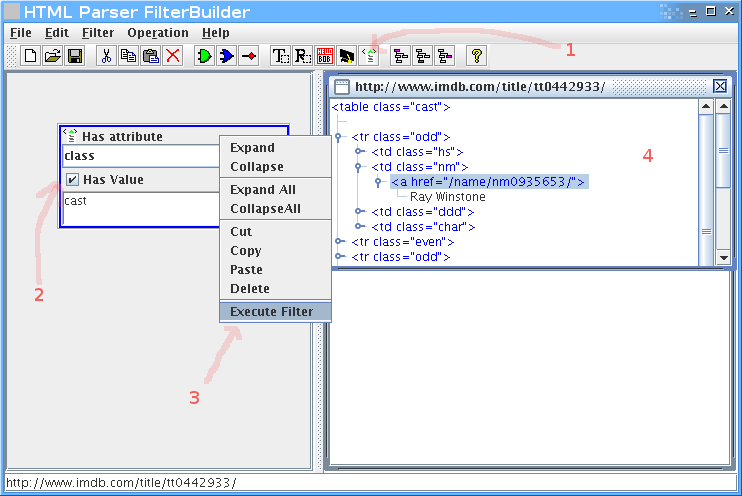
ברגע שיש לנו את הHTML, נתחיל לפלטר. חיפוש קצר אחרי שם של אחד השחקנים (Musician #2) מצא את הטבלא, ולמרבה הנוחות אפשר לראות שclass הCSS שלה הוא cast. זה מצויין, כי זה יאפשר לנו לדוג את הטבלא בקלות:
נוסיף פילטר של תכונות (attributes), נכניס בו את התכונה class עם הערך cast.
קליק ימני על הפילטר, execute filter, ונקבל חלון קטן בצד ימין עם התוצאות.
בינגו, יש לנו את הטבלה.
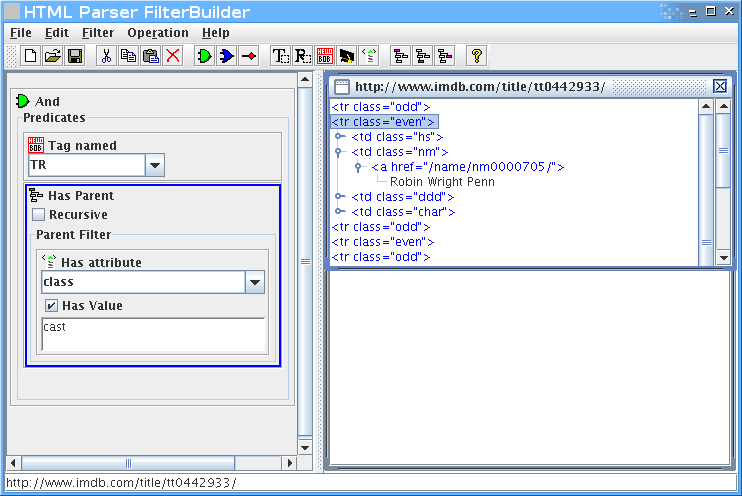
אבל אנחנו רוצים רק את רשימת השחקנים, אז צריך לעדן את הפילטר.
נוסיף שאנחנו רוצים רק טגים בשם TR, שיש להם הורה שהוא טבלא עם תכונה של class שערכו cast:
אפשר להמשיך, אבל הרעיון – אני מקווה – ברור.
ברגע שאנחנו מרוצים מהפילטר שיצרנו, אפשר לשמור אותו.
זה מה שיוצא (גרסא מקוצרת):
[code lang="java"]
// Generated by FilterBuilder. http://htmlparser.org
// [aced0005737200206f…….17374]
public class imdb
{
public static void main (String args[])
{
TagNameFilter filter0 = new TagNameFilter ();
filter0.setName ("TR");
HasAttributeFilter filter1 = new HasAttributeFilter ();
filter1.setAttributeName ("class");
filter1.setAttributeValue ("cast");
HasParentFilter filter2 = new HasParentFilter ();
filter2.setRecursive (false);
filter2.setParentFilter (filter1);
NodeFilter[] array0 = new NodeFilter[2];
array0[0] = filter0;
array0[1] = filter2;
AndFilter filter3 = new AndFilter ();
filter3.setPredicates (array0);
NodeFilter[] array1 = new NodeFilter[1];
array1[0] = filter3;
FilterBean bean = new FilterBean ();
bean.setFilters (array1);
if (0 != args.length)
{
bean.setURL (args[0]);
System.out.println (bean.getNodes ().toHtml ());
}
else
System.out.println ("Usage: java -classpath .:htmlparser.jar:htmllexer.jar imdb ");
}
}
[/code]
בראש הקובץ יש קידוד של הפילטר, מה שמאפשר לנו לטעון את הקובץ ולהמשיך לעבוד עליו מאותה נקודה.
כדי לקמפל את זה צריך כמובן את htmlfilter.jar בclasspath.
טוב, אז נניח שכתבנו פילטר מתאים, וגיבינו אותו בקצת קוד שמוציא את הנתונים לרשימה נוחה.
איך הופכים את זה לRSS?
בקלות, בעזרת ספרית ג'אווה בשם Rome.
השימוש ברומא פשוט מאוד, הנה דוגמא:
[code lang="java"]
public String getListRSS() throws FeedException
{
SyndFeed feed = new SyndFeedImpl();
feed.setFeedType("rss_2.0");
feed.setTitle("My RSS!");
feed.setLink("http://firefang.net/blog/768");
feed.setDescription("A feed for you!");
List entries = new ArrayList();
feed.setEntries(entries);
Vector v = new Vector();
v.add("item1");
v.add("item2");
v.add("item3");
for (int i = 0; i < v.size(); i++)
{
SyndEntry entry = new SyndEntryImpl();
entry.setTitle((String) v.elementAt(i));
entry.setLink("http:://imdb.com/");
entries.add(entry);
}
SyndFeedOutput output = new SyndFeedOutput();
return output.outputString(feed);
}
[/code]
שמפיקה את הRSS הזה:
[code lang="xml"]
My RSS!
http://firefang.net/blog/768
A feed for you! item1
http:://imdb.com/
http:://imdb.com/
item2
http:://imdb.com/
http:://imdb.com/
item3
http:://imdb.com/
http:://imdb.com/
[/code]
אז עכשיו שאנחנו יודעים לקחת דף HTML ולהוציא ממנו טקסט של RSS, נשאר רק לאפשר לקורא RSS רגילים לגשת אליו.
הדרך הטבעית תהיה להריץ שרת ווב קטן, שיגיש את קובץ הRSS למי שמבקש.
בחרתי להשתמש בJetty, שהוא שרת ווב קטן וגמיש בג'אווה, שמאפשר גם שילוב פשוט וקל בתוך אפליקציות אחרות.
לא להבהל מגודל ההורדה שלו, כדי להשתמש בו בתוך האפליקציה שלכם מספיק לקחת שלושה Jarים בגודל כולל של כ700K.
ככה משלבים את Jetty בתוך הישום שלכם, שימו לב כמה שזה פשוט.
[code lang="java"]
Handler handler=new AbstractHandler()
{
public void handle(String target, HttpServletRequest request, HttpServletResponse response, int dispatch)
throws IOException, ServletException
{
response.setContentType("text/html");
response.setStatus(HttpServletResponse.SC_OK);
response.getWriter().println("
Hello
");
((Request)request).setHandled(true);
}
}
Server server = new Server(8080);
server.setHandler(handler);
server.start();
[/code]
כדי לגשת אליו, נפתח את הדפדפן על http://localhost:8080 במקרה שלנו.
עכשיו רק נשאר לקשור את החוטים ביחד.
פתחתי בלוג קטן לפרוייקט, וחיש מהר החשבון שלי בTorrentLeech הושעה. כשביררתי מה הסיפור נאמר לי שהם חוששים שאני אגנוב למשתמשים סיסמאות.
הצעתי להם לבדוק את הקוד, ושעד אז אני אוריד את הלינק, וכך עשיתי, והחשבון שלי שוחזר.
בינתיים הם עדיין לא חזרו אלי, והסבלנות קצת פקעה.
מי שרוצה להוריד את הקוד יכול להוריד אותו מפה עם לקוח Subversion.
מי שרוצה להוריד את הבינארי מוזמן להוריד אותו מפה.
יש הוראות שימוש בתוך קובץ הREADME.
tl2rss משוחרר תחת רשיון GPL-3.0.
לאחר חודשים של עבודה מפרכת שחררתי היום את ספרית המפות מבוססת ה-Google Web Toolkit שלי. הספריה מאפשרת פיתוח אפליקציות web עם מפות בשפת Java (החביבה עלי וכן על עמרי עד מאוד), כשם ש-Google Maps API מאפשר זאת למפתחי JavaScript.
אחרי תקופת מעבר ארוכה בה מאמצי מנהלי הרשת הופנו לבניית השרתים החדשים, hcoop.net פותחים את השערים למשתמשים חדשים.
hcoop הוא ארגון שלא למטרות רווח שמספק שרותי הוסטינג במחיר עלות לכמה מאות גיקים (העלות מתחלקת בין החברים בhcoop).
אני מאכסן בhcoop את הבלוג הזה, את firestats.cc ועוד כמה אתרים שונים ומשונים, והכל במשהו כמו 5$ לחודש.
מה שחשוב לי במיוחד, זה שאני מקבל גישת shell ואפשרות להריץ למעשה כל דבר שאני רוצה על השרת.
מנהלי הרשת מאוד גמישים ואם יש לכם בקשה מיוחדת יש סיכוי טוב שהיא תקבל מענה מספק.
בנוסף hcoop מאפשרים מספר בלתי מוגבל של הוסטים וירטואליים, שזה דבר נוח מאוד.
hcoop מומלץ רק למשתמשים שלא חוששים משורת הפקודה ומקריאת תיעוד.