midp-build היא מערכת בילד לבנית פרוייקטי J2ME שמפותחים עם אקליפס.
פיתחתי את המערכת בוולי, שנסגרה לא מזמן – ולאחרונה קיבלתי אישור לשחרר אותה לחופשי.
המערכת מאוד גמישה, וכדאי לכל מי שמרגיש שהחיים שלו קשים מדי כשהוא בונה אפליקציות J2ME לנסות את midp-build.
The midp-build system is a generic build system for mobile java applications developed in Eclipse. it uses the Eclipse configuration files (.classpath files) to determine project dependency, build order and build classpath automatically.
it can build any MIDlet with very little configuration.
The system supports complex builds with multiple outputs, for example – it's possible to build for several products, configurations and devices in a single run.
The build fully support preprocessing of source code based on symbols that are defined per devices, products and configurations (or almost any combination of those).
The build allow fine customization of the properties contained in the JAD for each JAR+JAD pair generated.
The build supports signing of generated MIDlets automatically
The build supports including classpath resources in the generated JAR(s), and/or copying specific resources
The build supports local builds, based on files on the workspace (without changing them in any way).
The build fully supports CVS and have some untested support for SVN
The build supports multiple build configurations per Eclipse project (see conf.prefix)
אף פעם לא חיבבתי את XML.
העבודה עם השפה עצמה מסורבלת, קל מאוד לטעות ולדפוק קובץ שלם ויש יותר מדי תווים מיותרים שלא תורמים כלום לתוכן האמיתי.
אפילו השם מגעיל: איכס אמ אל.
יש נטייה להשתמש בXML כשפה לקבצי קונפיגורציה. אפשר לראות את זה בהמון פרוייקטים (למשל Tomcat ו Pidgin).
XML כשפה מנסה לפתור כל מני בעיות שלא מעניינות במיוחד את רוב המפתחים, ולכן המימוש של קוראי XML תקניים הוא מורכב.
הדבר במעצבן ביותר בXML היא שהיא קשה גם לאנשים שמנסים לקרוא אותה (או לשנות אותה), וגם למחשבים – או יותר נכון למפתחים – שמנסים לקרוא אותה.
ניקח לדוגמא את פיסת הXML הבאה (קוד אמיתי מההגדרות של טומקט):
הרבה מלל כדי להגיד שיש דבר כזה UserDatabase, ויש בתוכו שני זוגות Key-value, לא?
אפשר גם לציין את אותו מידע כך:
[code lang="java"]
ResourceParams{
UserDatabase{
factory : org.apache.catalina.users.MemoryUserDatabaseFactory
pathname : conf/tomcat-users.xml
}
}
[/code]
יותר קומפקטי ופחות פלצני.
השפה שבה השתמשתי בפעם השניה היא Swush, שפה שהגדרתי ומימשתי בסופ"ש.
Swush (סוו'ש בעברית, נראה לי שאני אדבוק באנגלית), תומכת בהערות בסגנון C/C++ וbash:
[code]
// C++ single line comment
/* C multi-
line comment*/
# Bash style comments
[/code]
בנוסף, סטרינגים בSwush לא מחייבים גרשיים, אבל אם משתמשים בגרשיים אפשר להגדיר סטרינגים עם רווחים ואפילו שורה-חדשה בתוכם.
[code]
string1
"another string"
"multi
line
string"
[/code]
המימוש שלי לSwush הוא בשפת ג'אווה, אבל בהחלט אפשרי שיהיו מימושים בשפות נוספות (בין אם שלי או של אנשים אחרים).
Swush תומך ברשימה פשוטה של מפתח-ערך, למשל:
[code lang="java"]
host : "locahost"
port : 8080
[/code]
ככה שאפשר בקלות רבה להחליף אותו קבצי properties של ג'אווה.
מבחינת הקוד, השתדלתי שהוא יהיה מה שיותר פשו לשימוש.
אפשר ליצור אובייקט Swush בכמה צורות:
[code lang="java"]
Swush fromFile = new Swush(new File(filename));
אחת הפונקציות המעניינות של המימוש שלי היא פונקציית select, שמחזירה רשימה של צמתים שמתאימים לקריטריות שצויין, לדוגמא – אם יש לנו קובץ Swush כזה:
[code lang="java"]
addressbook
{
max_size : 30
item
{
phone : 123
name : "The dude"
address : "Multi
Line address"
}
item
{
phone : 3454
name : "Another dude"
address : unknown
}
}
[/code]
ואנחנו רוצים לגשת לצמתים של הItem, נוכל לעשות משהו כזה:
[code lang="java"]
Swush swush = new Swush(new File(filename));
List matchs = swush.select("addressbook.item");
[/code]
הרשימה שחוזרת תכיל את שני הצמתים המתאימים (מסוג item שנמצאים בתוך addressbook).
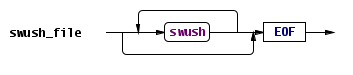
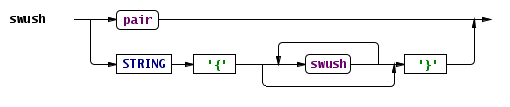
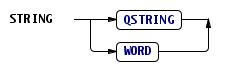
Swush ממומשת עם Antlr, וההגדרה שלה מאוד פשוטה, אפשר להעביר אותה בכמה דיאגרמות:
הPreprocessror שפיתחתי במסגרת העבודה של בVollee, שנכלל בפרוייקט הקוד הפתוח אנטנה (פרוייקט שעוזר בפיתוח ובבניה של ישומי ג'אווה למכשירים סלולריים), אושר על ידי Eclipse Legal, ויכלל בMTJ. MTJ הוא פרוייקט Eclipse רשמי שמטרתו להוסיף לEclipse תמיכה בפיתוח ישומי ג'אווה למכשירים סלולריים. כבר היום יש את EclipseME, פלאגין שפותח במשך שנים על ידי קרייג סטרה, שעושה את אותה עבודה – למעשה וקרייג עובד עם צוות MTJ, וMTJ מיועד להיות תחליף רשמי של EclipseME.
תהליך הקליטה של הPreprocessor לא היה קל:
הקוד המקורי הסתמך על ANTLR 2.7 (שמייצר אוטומטית קוד לפענוח קוד לפי הגדרה פורמלית – Parser generator) – הבעיה עם ANTLR 2.7 היתה שהרשיון שלו לא תאם את הרשיון של Eclipse (מסתבר שPublic domain זה לא תמיד טוב מספיק). למרבה המזל, ANTLR 3.0 כבר שוחרר ברשיון BSD שתאם את הרשיון של Eclipse, אבל הוא לא תאם את הקוד של הPreprocessor.
החב'רה בMTJ שאלו אם אני מוכן להמיר את הקוד כך שישתמש בANTLR 3.0: בינתיים עזבתי את Vollee ואת כל העולם של הפיתוח לסלולריים (בשעה טובה ומוצלחת) אז סירבתי, אבל אמרתי שאשמח לייעץ להם ולעזור מרחוק.
הם הרימו את הכפפה, וכמעט בלי עזרה מפתח אחד – דייגו סנדין – המיר את העסק לANTLR 3.0 תוך כשבועיים.
הזמן עבר, ולפני חודשיים צוות MTJ קיבל אישור למסור לי את הקוד, כדי שאקלוט אותו לתוך Antenna.
מכיוון שהקוד כלל בדיקות יחידה מקיפות, שדייגו הקפיד להשתמש בהן כדי לבדוק את ההמרה – התוצאה היתה טובה מאוד.
עוז זמן עבר, והיום הקוד קיבל אישור מEclipse Legal ויכנס לענף הראשי של MTJ.
כשכותבים בדיקת יחידה (Unit test) לקוד שקשור לבסיס נתונים, צריך לאתחל את בסיס הנתונים לאיזה שהוא מצב ידוע ויציב לפני כל בדיקה.
מול MySQL, אפשר להשתמש בmysql עצמו כדי ליבא סקריפט SQL מוכן, אבל זה לא נחמד במיוחד:
צריך לפתוח תהליך חדש, ויש כל מני בעיות מעצבנות עם זה (בג'אווה למשל, חובה לקרוא את הפלט של התהליך, אחרת הוא יתקע בכתיבה לפלט הסטנדרטי כשיתמלא הבאפר).
הרבה יותר נחמד יהיה ליבא את הקובץ ישירות מתוך ג'אווה, בשימוש בJDBC, לא?
הנה קוד שעושה בדיוק את זה, הוא מקבל זרם קלט (InputStream) שיכול להיות כל דבר, וגם Connection JDBC שחיברתם מבעוד מועד, וקולט את הSQL לתוך בסיס הנתונים.
הקוד מתמודד עם הפלט הסטנדרטי של mysqldump.
[code lang="java"]
public static void importSQL(Connection conn, InputStream in) throws SQLException
{
Scanner s = new Scanner(in);
s.useDelimiter("(;(\r)?\n)|(–\n)");
Statement st = null;
try
{
st = conn.createStatement();
while (s.hasNext())
{
String line = s.next();
if (line.startsWith("/*!") && line.endsWith("*/"))
{
int i = line.indexOf(' ');
line = line.substring(i + 1, line.length() – " */".length());
}
if (line.trim().length() > 0)
{
st.execute(line);
}
}
}
finally
{
if (st != null) st.close();
}
}
[/code]
אם יש משהו שאני אוהב בפרוייקטי קוד פתוח, זה שאנשים מוכנים לפעמים לעבוד די קשה כדי לשפר אותם.
את IP2C, ספריה למציאת המדינה של כתובת IP שחררתי לפני כמעט שנתיים, וכתבתי גם פוסט שמספר על המימוש שלה פה.
IP2C ממומשת בPHP ובג'אווה. מה שמיוחד בה זה שהיא מסוגלת לחפש ישירות על הקובץ, מה שאומר שחיפוש בודד הוא מאוד מהיר כי לא צריך להעלות את כל הקובץ לזכרון.
הייתי לגמרי מרוצה מהביצועים של הספריה בPHP (כ1200 חיפושים בשניה במחשב האחרון שמדדתי), אבל הביצועים בג'אווה היו טובים יותר משמעותית – כ8000 חיפושים בשניה על אותו מחשב בעבודה ישירות על קובץ הנתונים.
ההבדל בביצועים בין PHP לג'אווה לא הטריד אותי, כי היה לי ברור שPHP תהיה יותר איטית מג'אווה, אבל הוא כן הטריד את תומס רומר שהתיישב על העסק לילה שלם ושיפור את הביצועים של גרסאת הPHP ב150%.
תומס כתב פוסט מעניין על השינויים שהוא עשה, ושלח לי את השינויים. שבמבט ראשון נראים טובים ואני אקלוט אותם לפרוייקט אחרי בדיקה מעמיקה יותר.
בנוסף דיברנו קצת בIRC, והוא יעבוד על תמיכה בבסיס הנתונים של software77 :
software77 מספקים בסיס נתונים של IP למדינה, שאמור להיות יותר איכותי מבסיס הנתונים שIP2C משתמשת בו כרגע (webhosting.info), אבל יש להם קצת בעיות בעקביות המידע.
התחלתי לעבוד על תמיכה בבסיס הנתונים שלהם לפני כמה חודשים טובים, אבל כשראיתי שזה נמשך יותר מדי הקפאתי את העסק (שעדיין נמצא בTODO שלי, קבור איפשהו 🙂 )
תומס ימשיך מאיפה שהפסקתי.
הפוסט הזה מיועד למתכנתי ג'אווה שעובדים עם Eclipse.
אז אתם מתחילים פרוייקט, מפתחים, משתמשים בכל מני JARים מפרוייקטים אחרים בתוך הסביבת עבודה, מוסיפים פרוייקטים אחרים לרשימת התלויות של הפרוייקט שלכם, והכל עובד בתוך Eclipse.
ואז אתם צריכים לשחרר JAR שירוץ מחוץ לסביבת הפיתוח שלכם.
פה יש כמה אפשרויות:
1. להשתמש באופצית הExport JAR של Eclipse.
2. ליצור build.xml לפרוייקט
לפרוייקטים פשוטים, האפשרות הראשונה תספיק, אבל היא בהחלט לא עושה נעים בבטן. כדי ליצור את הJAR חייבים את Eclipse, וזה לא מאוד מיקצועי.
האפשרוית השניה היא מה שכמעט כולם עושים:
בדרך כלל מעתיקים build.xml מהפרוייקט השכן, ומתחילים לעקם אותו עד שיתאים לפרוייקט הנוכחי.
על הדרך עוד פעם מוסיפים – הפעם לbuild.xml החדש – את המסלול לJARים שהפרוייקט צריך כדי להתקמפל, ואולי גם את המסלול לספריות הbin של פרוייקטים אחרים שהפרוייקט הזה צריך, או אולי פשוט קריאה לקובץ הbuild.xml של הפרוייקטים האלו, ואז שימוש בתוצרים שלו.
אחרי זמן שיקח בין חצי שעה לחצי יום, תלוי בבלאגן שיש לכם בפרוייקט, כנראה תהיה לכם מערכת build עובדת לפרוייקט, שעושה בדיוק מה שאתם רוצים.
תהיה לכם תחושה נעימה בבטן, כי תוכלו לבנות את הפרוייקט שלכם מחוץ לEclipse (וככה גם אחרים אם בניתם את העסק נכון).
אבל מה, הפרוייקט ממשיך לחיות:
עם הזמן, נוספים לו תלויות בJARים נוספים, תלויות בפרוייקטים נוספים בסביבת העבודה וכו', ואז מערכת הבילד המדוגמת שלכם נשברת, ואתם מרגישים פיכס, כי שוב אי אפשר לבנות את העסק מחוץ לEclipse עד שתתקנו את הבילד.
הפעם בדרך כלל העידכון של הבילד הוא יותר פשוט, כמה דברים קטנים והכל עובד שוב.
עכשיו, תכפילו את כל העסק הזה במספר הפרוייקטים שאתם מפתחים אקטיבית על פני כמה שנים, ומתחיל להיות פה משהו די מעצבן.
הרבה קבצי build.xml שעושים כמעט אבל לא בדיוק את אותו דבר, והרבה התעסקות איתם ברגע שמשהו משתנה.
המפתח העצלן כבר מזמן שאל את עצמו: "מה, אין דרך אחרת?"
הרי לרוב הפרוייקטים, Eclipse מכיל את כל המידע שצריך בשביל לבנות אותם.
מעבר לזה, המידע הזה תמיד נכון בהגדרה כי אחרת לא תוכלו לפתח כלום וזה יהיה הדבר הראשון שתתקנו ברגע שתעשו איזה שינוי.
Eclipse שומר את רוב המידע בתוך קבצי ה.claspath בתוך כל פרוייקט (וגם קצת בתוך קבצי ה.project). הקבצים האלו הם קבצי XML פשוטים למדי, שלא השתנו משמעותית מאז ימי Eclipse הראשונים.
אז הנה רעיון:
מה אם במקום לשכפל את המידע גם בEclipse וגם בbuild.xml, ניצור build.xml אחד שקורא את המידע על הפרוייקטים מEclipse, מבין מה סדר הבניה הנכון של הפרוייקטים, איזה JARים צריך לכל פרוייקט ובונה את העסק לפי זה?
אותו build.xml קסום ומופלא יעבוד כמעט לכל פרוייקט Java שפותח בתוך Eclipse בצורה שקופה, בלי שום התעסקות ותחזוקה של קובץ build.xml ספציפי לפרוייקט.
נשמע טוב מכדי להיות אמיתי?
ובכן, שחררתי מערכת כזו בדיוק, ולמערכת קוראים ebuild.
התחלתי לפתח אותה לפני שנים, והיא ליוותה אותי דרך ארבע מקומות עבודה עד עכשיו (למעשה דרך כל מקומות העבודה שהיו לי בתחום ההיטק).
המערכת משוחררת תחת רשיון FreeBSD (רשיון תעשו מה שבזין שלכם, לא מזיז לי) ודף הבית שלה הוא http://ebuild.firefang.net.
בגדול, כדי להשתמש בה, מה שצריך לעשות זה:
לקחת את הקוד שלה ולהכניס לפרוייקט נפרד בסביבת העבודה.
להעתיק את example-common.properties לcommon.properties (הוא מכיל הגדרות ספציפיות למחשב שלכם, למרות שכרגע אין מה להתעסק איתו ברוב המקרים).
ליצור קובץ build.properties בתוך הפרוייקט שאתם בונים (מאוד פשוט ומינימלי)
להריץ עם ant -Dproject=YOUR_PROJECT, כאשר YOUR_PROJECT הוא השם שם הפרוייקט שלכם בסביבת העבודה.
לקחת את התוצרים האיכותיים מספרית הbuild שנוצרה תחת הפרויקט.
התוצר יהיה JAR שניתן להריץ בעזרת java -jar file.jar, וכן זיפ שכולל את הJAR ואת הספריות הדרושות כדי להפיץ את התוכנית.
נכון לכרגע, המערכת די בסיסית ומסוגלת לבנות פרוייקטי Eclipse בתוך סביבת העבודה (Workspace) שלכם.
בהמשך אני מתכנן להוסיף אפשרות לתייג פרוייקטם ולבנות ישר מCVS/SVN בלי לגעת בקוד בסביבת העבודה (זה דרוש כדי לשחרר גרסאות בצורה מסודרת).
בנוסף, אני מתכנן להוסיף אפשרות לebuild-hook.xml אופציונלי שיהיה ספציפי לפרוייקט שיכיל כל מני דברים שבאמת ספציפיים לפרוייקט מסויים.
יש כמה דברים שכדאי לדעת:
באופן כללי, עדיף לעבוד עם JARים שנמצאים בתוך בworkspace כי אז החיים של מי שרוצה לבנות את העסק הם יותר קלים.
ebuild תומך בזה בצורה טובה, אבל לא ברור לי אם הוא יתמודד עם JARים חיצוניים.
ebuild לא תומך בכל מני הרחבות מוזרות של eclipse, שמסתמכות על מידע שלא מופיע בקבצי ה.classpath. למשל 'user libraries'. אם אתם רוצים שהוא יעבוד בשבילכם, תעבדו פשוט.
זהו.
אני אשמח אם הרבה אנשים ישתמשו בebuild, ידווחו על בעיות ואולי אפילו ישלחו תיקונים.
כולם יודעים שC יותר מהירה מג'אווה, נכון?
פרוייקטים רציניים של גריסת מספרים (Number crunching) כמו עיבוד תמונה בזמן אמת, זיהוי קול, רינדור, דחיסה, קידוד ווידאו וכו בדרך כלל נכתבים בC (או C++).
בהינתן שתי פיסות קוד שעושות בדיוק את אותו דבר, מעניין לראות את במה מתבטא היתרון של C על ג'אווה.
למה אפשר לצפות ליתרון?
כי ג'אווה רצה מעל JVM, והJVM מוסיף תקורה, ברור שC תרוץ יותר מהר כי היא רצה ישר על הCPU ולא דרך הJVM.
הנה שתי פיסות קוד, אחת בג'אווה ואחת בC. שתי התוכניות מאתחלות שתי מטריצות גדולות ומכפילות אותן אחת בשניה, הקוד בהחלט לא יעיל במיוחד ברמת האלגוריתם, אבל הוא זהה מבחינה מימושית.
הנה הקוד:
תוכנית C:
[code lang="c"]
#include
#include
int main(int argc, char **argv)
{
int i,j,k;
int N = 2500;
printf("N = %d\n", N);
double *A = malloc(N*N*sizeof(double));
double *B = malloc(N*N*sizeof(double));
double *C = malloc(N*N*sizeof(double));
double *bj = malloc(N*sizeof(double));
for (i = 0; i < N; i++)
for (j = 0; j < N; j++)
{
int n = i*N+j;
A[n] = i * j;
}
for (i = 0; i < N; i++)
for (j = 0; j < N; j++)
B[i*N+j] = i * j * j;
// order 7: jik optimized ala JAMA
for (j = 0; j < N; j++) {
for (k = 0; k < N; k++)
bj[k] = B[k*N+j];
for (i = 0; i < N; i++) {
double s = 0;
for (k = 0; k < N; k++) {
s += A[i*N+k] * bj[k];
}
C[i*N+j] = s;
}
}
printf("done\n");
return 0;
}
[/code]
תוכנית ג'אווה:
[code lang="java"]
public class Matrix
{
public static void main(String[] args)
{
int i,j,k;
int N = 2500;
System.err.println("N = " + N);
double A[] = new double[N*N];
double B[] = new double[N*N];
double C[] = new double[N*N];
double bj[] = new double[N];
for (i = 0; i < N; i++)
for (j = 0; j < N; j++)
{
int n = i*N+j;
A[n] = i * j;
}
for (i = 0; i < N; i++)
for (j = 0; j < N; j++)
B[i*N+j] = i * j * j;
// order 7: jik optimized ala JAMA
for (j = 0; j < N; j++) {
for (k = 0; k < N; k++)
bj[k] = B[k*N+j];
for (i = 0; i < N; i++) {
double s = 0;
for (k = 0; k < N; k++) {
s += A[i*N+k] * bj[k];
}
C[i*N+j] = s;
}
}
System.err.println("done");
}
}
[/code]
מי לוקח התערבות של בכמה C עוקפת את ג'אווה בזמן הריצה של זה?
נקמפל ונבדוק:
[code]
$javac Matrix.java
$gcc Matrix.c -o matrix
$ date;java Matrix;date;./matrix;date
Thu Jun 26 08:42:10 IDT 2008
N = 2500
done
Thu Jun 26 08:42:54 IDT 2008
N = 2500
done
Thu Jun 26 08:44:31 IDT 2008
[/code]
לתוכנית בג'אווה לקח לקח 44 שניות ולתוכנית בC לקח 107 שניות.
מש"ל.
אה, רגע. רצינו להראות שC יותר מהירה!
טוב, מסתבר שלא כדאי לקחת דברים כמובנים מאליהם, גם אם כולם יודעים שהם נכונים.
אם אתם חושבים שרימיתי, תריצו בעצמכם. בדקתי על שני מחשבים, אחד עם שתי ליבות של 3GHZ, ואחד עם ארבע ליבות של 2.4GHZ (כמובן שהראשון הוביל בכמה אחוזים טובים, אבל היחס נשמר).
השתמשתי בJava 1.6.06.
לדעתי התופעה הזו נובעת מההתקדמות המדהימה של סביבת הריצה של ג'אווה בתחום הHotspot.
Hotspot היא טכנולוגיה שמקמפלת חלקים "חמים" בתוכנית בזמן, אבל בזמן ריצה. מכיוון שזמינות לHotspot סטטיסטיקות בזמן הריצה הממשי של התוכנית היא יכולה לשנות את הקוד ככה שירוץ בצורה אופטימלית לאור התנהגות של התוכנית ולא כנסיון מלומד לנחש מה יהיה יותר מהר מהתבוננות ושינוי הקוד, מה שעושה קומפיילר סטאטי.
עדכון:
קימפלתי את התוכנית C עם אופטימיזציה מקסימלית והתוצאה שלה השתפרה פלאים:
[code]
gcc -O3 Matrix.c
$ date;./matrix;date
Thu Jun 26 11:26:00 IDT 2008
N = 2500
done
Thu Jun 26 11:26:29 IDT 2008
[/code]
הפעם התוצאה של C היא 29 שניות.
טוב משמעותית מקודם, וגם יותר מהיר בכ30% מג'אווה.
עדכון 2:
שמתי לב שקוד שקומפל עם javac איטי מקוד שקומפל בeclipse. נחשתי שeclipse מקמפל עם jikes (אני לא בטוח בזה).
ניסיתי עם jikes והתוצאה השתוותה, תיקו 29 שניות.
[code]
$ javac Matrix.java ; time java Matrix
N = 2500
done
real 0m42.854s
user 0m55.335s
sys 0m26.214s
$ jikes --bootclasspath /usr/lib/jvm/java-6-sun-1.6.0.06/jre/lib/rt.jar Matrix.java ; time java Matrix
N = 2500
done
real 0m29.463s
user 0m29.366s
sys 0m0.108s
[/code]
אגב, זו תוצאה מדהימה שכדאי שכל מפתח ג'אווה יכיר.
מי רוצה לשפר את התוצאות עוד?
אחרי ניג'וסים ונדנודים, החברים בTorrentLeech בדקו את TorrentLeech2RSS ואישרו אותו לשימוש (כאילו, יכלתי לשחרר אותו בלי לומר להם, אבל אז הם היו משעים לי שוב את החשבון).
אז בקיצור, מי שרוצה להוריד, שיתכבד ויפנה לבלוג של הפרוייקט.
לפני כמה שבועות הפיד RSS של TorrentLeech (להלן TL), ספק הסדרות העיקרי שלי, התחיל להחזיר 404 (דף לא נמצא).
אין פה שום דבר חדש, הפיד הזה אף פעם לא היה יציב במיוחד, לכן חיכיתי בסבלנות כשבוע, ואז התלוננתי בערוץ הIRC שהלינק של הפיד לא עובד.
גורם "רשמי" מסר לי שהפיד לא יחזור כי השתמשו בו לרעה.
ניסיתי לברר את פשר השימוש הפוחז, ואפילו הצעתי את עזרתי במציאת פיתרון, אך לשוא:
הילדון זב החוטם מסר שלא משנה מה אני אגיד או אעשה, הפיד לא חוזר.
הסברתי לו בדרכי נועם שאם המידע זמין באתר, אין שום הבדל כי אפשר להפוך אותו לפיד, אבל זה לא עזר.
אז החלטתי לעשות בדיוק את זה, וכך נולדה תוכנה חדשה – TorrentLeech2RSS.
בגדול, הרעיון הוא כזה:
שרת מקומי דוגם את TL, נניח פעם בחצי שעה.
השרת נכנס לTL, מזדהה עם שם המשתמש והסיסמא של המשתמש בTL, מוריד את דף הHTML שמכיל את רשימת הטורנטים בכל אחת מהקטגוריות הנבחרות, מפענח את הדף, ומחלץ ממנו את השם, הלינק, המזהה והתאריך של כל טורנט, ושומר אותם בזכרון.
במקום להשתמש בכתובת הRSS של TL (שאינה עימנו עוד), המשתמש מכניס כתובת של TorrentLeech2RSS, שמכין דף RSS ומחזיר אותו למבקש.
TorrentLeech2RSS גם משכתב את הלינקים בתוך הRSS שיעברו דרכו, כדי שיוכל להוסיף פרטי הזדהות שיעברו לשרת של TL ברגע שהמשתמש מנסה להוריד טורנט (אחרת הTracker של TL לא משתף פעולה עם המשתמש).
בחרתי לכתוב את tl2rss בשפת ג'אווה.
הצעד הראשון, וכנראה הכי קשה בתהליך, הוא להכנס תכנותית לאתר, התהליך מורכב יחסית וכולל כמה שלבים.
כדי להבין מה אני אמור לשלוח ומתי, השתמשתי בWireShark, וניטרתי את התעבורה שנוצרת כשאני מבצע לוגין בעזרת הדפדפן.
שימו לב במיוחד לאפשרת של Follow TCP Stream, שמציגה שיחת HTTP שלמה בצורה ברורה.
ברגע שהקוד הצליח להזדהות מול השרת, לבקש דף שמתאים לקטגוריה רלוונטית זה קל. אבל מה עושים עם הדף?
הדפים של TorrentLeech הם דוגמא לאיך נראה קוד HTML מבולגן ולא תקני, ערבוביה של תגיות HTML שכוללות תוכן, עיצוב ועימוד.
בקיצור, לא משהו שכיף במיוחד לחפוש בתוכו אחרי מידע.
הגישה הנאווית לבעיות כאלו היא שימוש בביטוי רגולרי, אבל זה לא יעבוד טוב בכל המקרים (מה קורה למשל אם יש HTML בתוך התאור של הטורנט?).
בחרתי ללכת לגישה טיפה יותר חזקה, והיא פירוק מלא של הHTML למבנה נתונים בזכרון, וניתוח של אותו מבנה.
ספרית ג'אווה שמאפשרת parsing כזה לHTML היא htmlparser הוותיקה.
אבל גם אם htmlparser מחזירה לנו עץ אובייקטים נוח, איך מוציאים ממנו את מה שמעניין? הוא ענק וסבוך ויותר מכל מסובך.
למזלי מצאתי בונה פילטרים ויזואלי עם htmlparser. אפשר להריץ אותו עם Java web start:
[code]
javaws http://htmlparser.sourceforge.net/samples/filterbuilder.jnlp
[/code]
או פשוט להריץ את הקוד ישירות (org.htmlparser.parserapplications.filterbuilder.FilterBuilder). עורך הפילטרים מאפשר ליצור פילטרים מורכבים בהדרגתיות תוך בדיקה מתמדת של התוצאה על דף הHTML שאתם רוצים לבדוק.
אזהרה: הוא לא הכי ידידותי בעולם, לוקח זמן להתרגל אליו – אבל הוא עובד.
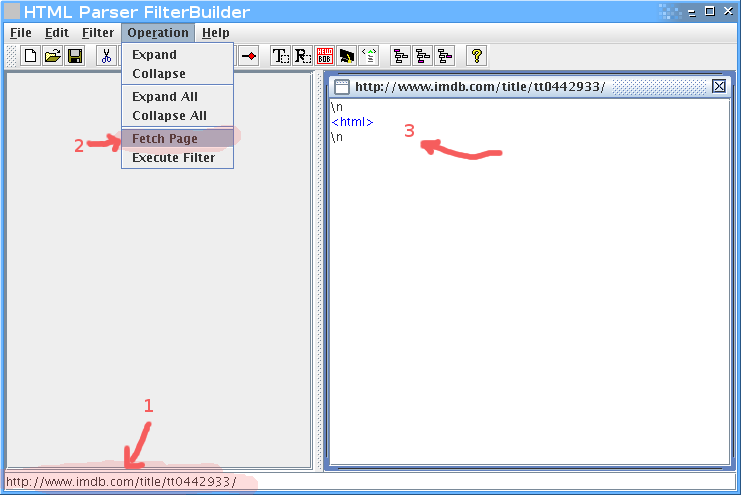
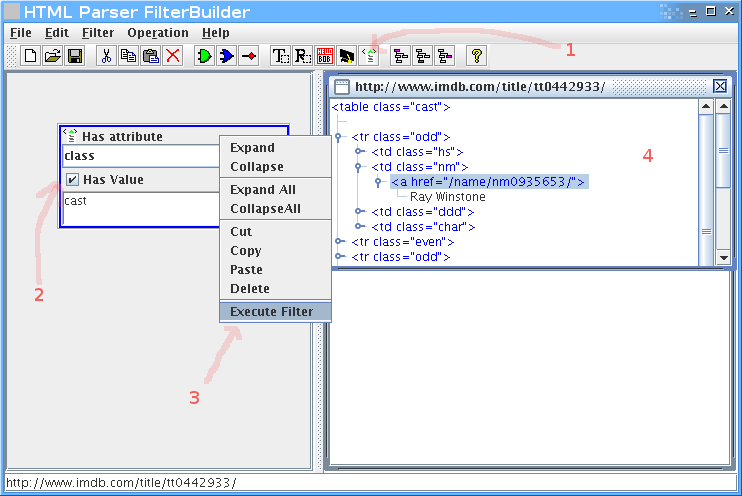
לדוגמא, נניח שאנחנו רוצים לחלץ את רשימת השחקנים מהסרט ביוולף בIMDB.
קודם נכניס בשורה התחתונה את הURL, אחר כך נלחץ על fetch page, ואז נקבל את הHTML כעץ בחלק הימני.
ברגע שיש לנו את הHTML, נתחיל לפלטר. חיפוש קצר אחרי שם של אחד השחקנים (Musician #2) מצא את הטבלא, ולמרבה הנוחות אפשר לראות שclass הCSS שלה הוא cast. זה מצויין, כי זה יאפשר לנו לדוג את הטבלא בקלות:
נוסיף פילטר של תכונות (attributes), נכניס בו את התכונה class עם הערך cast.
קליק ימני על הפילטר, execute filter, ונקבל חלון קטן בצד ימין עם התוצאות.
בינגו, יש לנו את הטבלה.
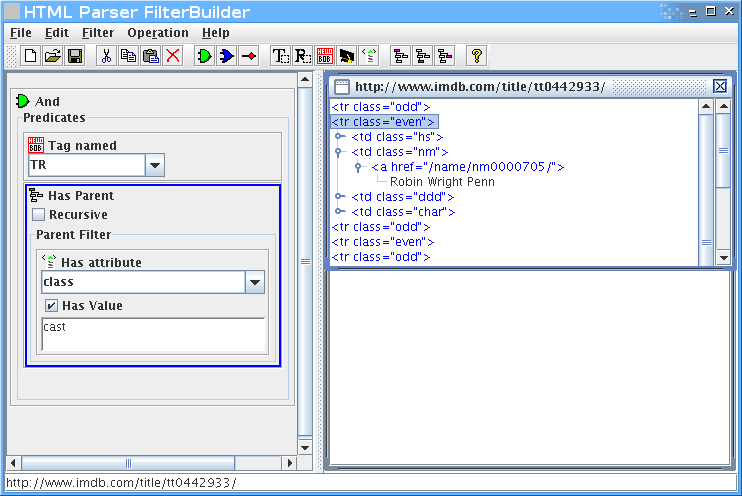
אבל אנחנו רוצים רק את רשימת השחקנים, אז צריך לעדן את הפילטר.
נוסיף שאנחנו רוצים רק טגים בשם TR, שיש להם הורה שהוא טבלא עם תכונה של class שערכו cast:
אפשר להמשיך, אבל הרעיון – אני מקווה – ברור.
ברגע שאנחנו מרוצים מהפילטר שיצרנו, אפשר לשמור אותו.
זה מה שיוצא (גרסא מקוצרת):
[code lang="java"]
// Generated by FilterBuilder. http://htmlparser.org
// [aced0005737200206f…….17374]
public class imdb
{
public static void main (String args[])
{
TagNameFilter filter0 = new TagNameFilter ();
filter0.setName ("TR");
HasAttributeFilter filter1 = new HasAttributeFilter ();
filter1.setAttributeName ("class");
filter1.setAttributeValue ("cast");
HasParentFilter filter2 = new HasParentFilter ();
filter2.setRecursive (false);
filter2.setParentFilter (filter1);
NodeFilter[] array0 = new NodeFilter[2];
array0[0] = filter0;
array0[1] = filter2;
AndFilter filter3 = new AndFilter ();
filter3.setPredicates (array0);
NodeFilter[] array1 = new NodeFilter[1];
array1[0] = filter3;
FilterBean bean = new FilterBean ();
bean.setFilters (array1);
if (0 != args.length)
{
bean.setURL (args[0]);
System.out.println (bean.getNodes ().toHtml ());
}
else
System.out.println ("Usage: java -classpath .:htmlparser.jar:htmllexer.jar imdb ");
}
}
[/code]
בראש הקובץ יש קידוד של הפילטר, מה שמאפשר לנו לטעון את הקובץ ולהמשיך לעבוד עליו מאותה נקודה.
כדי לקמפל את זה צריך כמובן את htmlfilter.jar בclasspath.
טוב, אז נניח שכתבנו פילטר מתאים, וגיבינו אותו בקצת קוד שמוציא את הנתונים לרשימה נוחה.
איך הופכים את זה לRSS?
בקלות, בעזרת ספרית ג'אווה בשם Rome.
השימוש ברומא פשוט מאוד, הנה דוגמא:
[code lang="java"]
public String getListRSS() throws FeedException
{
SyndFeed feed = new SyndFeedImpl();
feed.setFeedType("rss_2.0");
feed.setTitle("My RSS!");
feed.setLink("http://firefang.net/blog/768");
feed.setDescription("A feed for you!");
List entries = new ArrayList();
feed.setEntries(entries);
Vector v = new Vector();
v.add("item1");
v.add("item2");
v.add("item3");
for (int i = 0; i < v.size(); i++)
{
SyndEntry entry = new SyndEntryImpl();
entry.setTitle((String) v.elementAt(i));
entry.setLink("http:://imdb.com/");
entries.add(entry);
}
SyndFeedOutput output = new SyndFeedOutput();
return output.outputString(feed);
}
[/code]
שמפיקה את הRSS הזה:
[code lang="xml"]
My RSS!
http://firefang.net/blog/768
A feed for you! item1
http:://imdb.com/
http:://imdb.com/
item2
http:://imdb.com/
http:://imdb.com/
item3
http:://imdb.com/
http:://imdb.com/
[/code]
אז עכשיו שאנחנו יודעים לקחת דף HTML ולהוציא ממנו טקסט של RSS, נשאר רק לאפשר לקורא RSS רגילים לגשת אליו.
הדרך הטבעית תהיה להריץ שרת ווב קטן, שיגיש את קובץ הRSS למי שמבקש.
בחרתי להשתמש בJetty, שהוא שרת ווב קטן וגמיש בג'אווה, שמאפשר גם שילוב פשוט וקל בתוך אפליקציות אחרות.
לא להבהל מגודל ההורדה שלו, כדי להשתמש בו בתוך האפליקציה שלכם מספיק לקחת שלושה Jarים בגודל כולל של כ700K.
ככה משלבים את Jetty בתוך הישום שלכם, שימו לב כמה שזה פשוט.
[code lang="java"]
Handler handler=new AbstractHandler()
{
public void handle(String target, HttpServletRequest request, HttpServletResponse response, int dispatch)
throws IOException, ServletException
{
response.setContentType("text/html");
response.setStatus(HttpServletResponse.SC_OK);
response.getWriter().println("
Hello
");
((Request)request).setHandled(true);
}
}
Server server = new Server(8080);
server.setHandler(handler);
server.start();
[/code]
כדי לגשת אליו, נפתח את הדפדפן על http://localhost:8080 במקרה שלנו.
עכשיו רק נשאר לקשור את החוטים ביחד.
פתחתי בלוג קטן לפרוייקט, וחיש מהר החשבון שלי בTorrentLeech הושעה. כשביררתי מה הסיפור נאמר לי שהם חוששים שאני אגנוב למשתמשים סיסמאות.
הצעתי להם לבדוק את הקוד, ושעד אז אני אוריד את הלינק, וכך עשיתי, והחשבון שלי שוחזר.
בינתיים הם עדיין לא חזרו אלי, והסבלנות קצת פקעה.
מי שרוצה להוריד את הקוד יכול להוריד אותו מפה עם לקוח Subversion.
מי שרוצה להוריד את הבינארי מוזמן להוריד אותו מפה.
יש הוראות שימוש בתוך קובץ הREADME.
tl2rss משוחרר תחת רשיון GPL-3.0.