שוחררה הגרסא האחרונה (ככל הנראה) בענף של PHP 4.4.
הגרסא הזו מסמנת את סוף התמיכה הרשמית בPHP4.
PHP5 כבר בחוץ במשך יותר משלוש שנים, אבל עד עכשיו האימוץ שלו היה די איטי, מסיבות של ביצה ודינוזאור:
מפתחי התוכנות לא רצו להפסיק לתמוך בPHP4 כדי לא לאבד משתמשים. חברות אירוח האתרים לא טרחו לשדרג כי כל התוכנות החשובות תמכו גם ככה בPHP4 והמשתמשים, מה איכפת להם?
בשנה שעברה נפתח אתר gophp5.org, ששם לעצמו למטרה לדחוף את האימוץ של PHP5.
הרעיון הוא שאם מסה מספיק גדולה של פרוייקטים תעבור לPHP5, ומסה מספיק גדולה של חברות אירוח תעבור לPHP5, לשאר חברות האירוח לא תהיה ברירה והן תאלצנה לשדרג או לאבד משתמשים, ואז לשאר הפרוייקטים לא תהיה סיבה להשאר בPHP4 והם יוכלו להתחיל סוף סוף לנצל את היכולות של PHP5.
בפברואר 2008 כבר היו מעל 100 פרוייקטי תוכנה שהתחייבו להפסיק לדאוג לתמיכה בPHP4 (זה לא אומר שהם ילכו וישברו את התמיכה בPHP4 בכוונה, פשוט שהם יפסיקו לדאוג שקוד חדש ירוץ בPHP4), ומעל 200 חברות איכסון שתומכות בPHP 5.2 כביררת מחדל וgophp5 טענו להצלחה והפסיקו לאסוף הרשמות.
אז למה לא לתמוך בPHP4? הנה דוגמא מאתמול:
JSON הוא דרך להעביר מבנה נתונים כלשהו לייצוג של מבנה הנתונים כאובייקט ג'אווה סקריפט, והוא אחת הדרכים הפשוטות והיעילות ביותר להעביר נתונים מקוד בצד השרת לדפדפן (שפשוט מפעיל על הטקסט שחוזר את המפסק (parser) של ג'אווה סקריפט כדי לקבל אובייקט מוכן לשימוש.
למרות שראשי התיבות של AJAX הן Asynchronous Javascript And XML, מעולם לא השתמשתי בAJAX כדי להעביר XML, למעשה אני מוצא את הרעיון מזעזע. הרבה יותר קל להעביר JSON, או אפילו קוד HTML ממש.
JSON משמש בהרבה מאוד פרוייקטים מבוססי AJAX, ומכיוון שאין בPHP4 תמיכה מובנית בJSON (אחרי הכל, PHP4 הוא בן שמונה, וJSON הוא די חדש בשכונה) צריך להשתמש בספריות חיצוניות שיודעות להעביר אובייקט PHP לפורמט JSON, אחת הספריות הנפוצות היא Services_JSON (למעשה אני משתמש בספריה הזו בFireStats).
הספריה כתובה בPHP, ולמרות שהיא עובדת נכון, היא לא ממש עובדת מהר, במיוחד כשממירים מבני נתונים גדולים (לא עצומים, משהו בסדר גודל של מערך עם 1000 אובייקטים טיפה מורכבים) לJSON.
ממש אתמול ניסיתי לשפר ביצועים של ישום PHP, אחרי חפירות גיליתי שאחד הדברים שמאטים מאוד את העסק היה המרה של תשובה לדפדפן לJSON בשימוש בServices_JSON, כשאני אומר איטי, אני מתכוון ל8 שניות.
שמונה שניות שהשרת טוחן את הCPU שלו כדי להכין תשובה ללקוח (במקרה הספציפי הזה, במקרים אחרים עם יותר נתונים זה כמובן יותר גרוע).
ברגע שראיתי את זה, לקח לי בדיוק שניה וחצי להיזכר שPHP5 תומך בJSON. בדיקה מהירה בphp.net הניבה את שתי הפונקציות הפשוטות json_encode וjson_decode. החלפתי את השימוש ב Services_JSON בקריאה לפונקציות של php5, ולא הייתי מופתע במיוחד לראות שהמרה של אותו מבנה נתונים לוקחת פתאום 40 מילישניות.
שיפור של פי 200, בזמן עבודה של כמה שניות (טוב, חוץ מלמצוא את הבעיה 🙂 )
השיפור נובע מכך שהתמיכה של PHP בJSON לא כתובה בPHP אלא בC, ולכן היא הרבה הרבה יותר יעילה.
השיפור הזה התאפשר רק כי הפרוייקט הספציפי הזה לא צריך לתמוך בPHP4.
מה אני אצטרך לעשות בFireStats, שעדיין תומך בPHP4 כדי להנות מהשיפור הזה? לבדוק אם אני על PHP5, ואם כן להשתמש בפונקציות האלו אחרת להשתמש בServices_JSON. לא כיף במיוחד.
ואם לא היתה לי סיפריה כמו Services_JSON (כי אין, או כי תנאי הרשיון לא מתאימים לי), הייתי נאלץ לכתוב אחת או פשוט לעבוד בצורה אחרת, פחות נוחה. גם לא כיף.
אז איך מתקדם האימוץ של PHP5?
החל מFireStats 1.3 ששחרתי לפני יותר משנה, FireStats מכילה רכיב ששולח (באישור המשתמש) מידע מערכת אנונימי. חלק מהמידע הוא גרסאות הPHP והMySQL.
הכוונה היא שאני אוכל להשתמש במידע הזה כדי להחליט בצורה יותר מושכלת במה אני צריך לתמוך.
המידע הצטבר לי בבסיס הנתונים, ונכון לכרגע יש לי מידע על כמעט 12000 התקנות. מה שאומר כמעט 12000 שרתים בעולים (אני מתעלם ממקרים של כמה התקנות על אותו שרת).
למי שתוהה, זה לא אומר שFireStats הותקנה 12000 פעמים, אלא ש12000 פעמים המתקינים הסכימו לשלוח מידע מערכת אנונימי.
מי שרוצה את המידע הגולמי מוזמן לקחת אותם מפה (יצוא MSQL, כ5 מגה דחוסים, 65 מגה פרושים).
אז ישבתי כמה שעות כדי להוציא מהנתונים הגולמיים שני גרפים נחמדים:
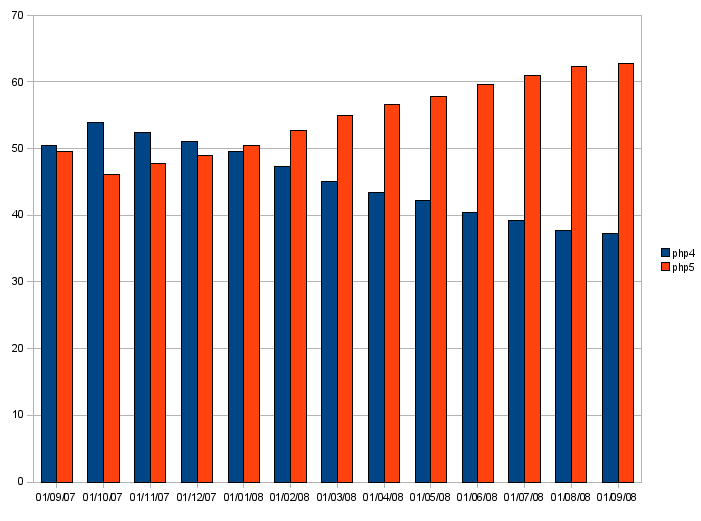
הראשון הוא אחוזי ההתקנות של PHP 4 מול PHP 5, במהלך השנה האחרונה.
למרות שאחוזי ההתקנה של PHP4 ירדו במהלך השנה האחרונה מ52% ל38%, עדיין מי אי אפשר להתעלם ממנו. נקווה שהוא ימות סופית בקרוב:
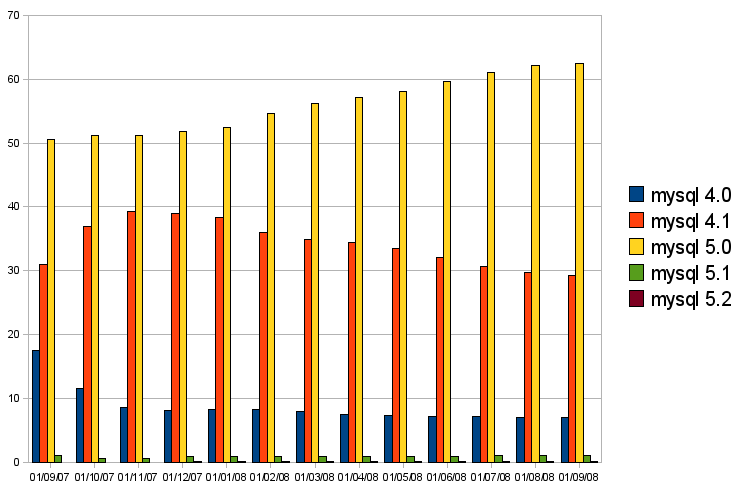
השני הוא אחוזי ההתקנות של הגרסאות המשמעותיות של MYSQL:
כיף לראות שMYSQL 5.0 שולט בשוק, אבל נראה שMYSQL 4.0 הזוועתי נתקע על 7% ולא רוצה למות.
בכל מקרה, MYSQL 4.0 הוא בהחלט מועמד לנטישה, וכבר היום יש לא מעט תכונות חשובות של FireStats שלא נתמכות בגרסא הזו.