אחרי ניג'וסים ונדנודים, החברים בTorrentLeech בדקו את TorrentLeech2RSS ואישרו אותו לשימוש (כאילו, יכלתי לשחרר אותו בלי לומר להם, אבל אז הם היו משעים לי שוב את החשבון).
אז בקיצור, מי שרוצה להוריד, שיתכבד ויפנה לבלוג של הפרוייקט.
איך להוציא RSS מאתר שלא תומך בRSS?
לפני כמה שבועות הפיד RSS של TorrentLeech (להלן TL), ספק הסדרות העיקרי שלי, התחיל להחזיר 404 (דף לא נמצא).
אין פה שום דבר חדש, הפיד הזה אף פעם לא היה יציב במיוחד, לכן חיכיתי בסבלנות כשבוע, ואז התלוננתי בערוץ הIRC שהלינק של הפיד לא עובד.
גורם "רשמי" מסר לי שהפיד לא יחזור כי השתמשו בו לרעה.
ניסיתי לברר את פשר השימוש הפוחז, ואפילו הצעתי את עזרתי במציאת פיתרון, אך לשוא:
הילדון זב החוטם מסר שלא משנה מה אני אגיד או אעשה, הפיד לא חוזר.
הסברתי לו בדרכי נועם שאם המידע זמין באתר, אין שום הבדל כי אפשר להפוך אותו לפיד, אבל זה לא עזר.
אז החלטתי לעשות בדיוק את זה, וכך נולדה תוכנה חדשה – TorrentLeech2RSS.
בגדול, הרעיון הוא כזה:
שרת מקומי דוגם את TL, נניח פעם בחצי שעה.
השרת נכנס לTL, מזדהה עם שם המשתמש והסיסמא של המשתמש בTL, מוריד את דף הHTML שמכיל את רשימת הטורנטים בכל אחת מהקטגוריות הנבחרות, מפענח את הדף, ומחלץ ממנו את השם, הלינק, המזהה והתאריך של כל טורנט, ושומר אותם בזכרון.
במקום להשתמש בכתובת הRSS של TL (שאינה עימנו עוד), המשתמש מכניס כתובת של TorrentLeech2RSS, שמכין דף RSS ומחזיר אותו למבקש.
TorrentLeech2RSS גם משכתב את הלינקים בתוך הRSS שיעברו דרכו, כדי שיוכל להוסיף פרטי הזדהות שיעברו לשרת של TL ברגע שהמשתמש מנסה להוריד טורנט (אחרת הTracker של TL לא משתף פעולה עם המשתמש).
בחרתי לכתוב את tl2rss בשפת ג'אווה.
הצעד הראשון, וכנראה הכי קשה בתהליך, הוא להכנס תכנותית לאתר, התהליך מורכב יחסית וכולל כמה שלבים.
כדי להבין מה אני אמור לשלוח ומתי, השתמשתי בWireShark, וניטרתי את התעבורה שנוצרת כשאני מבצע לוגין בעזרת הדפדפן.
שימו לב במיוחד לאפשרת של Follow TCP Stream, שמציגה שיחת HTTP שלמה בצורה ברורה.
ברגע שהקוד הצליח להזדהות מול השרת, לבקש דף שמתאים לקטגוריה רלוונטית זה קל. אבל מה עושים עם הדף?
הדפים של TorrentLeech הם דוגמא לאיך נראה קוד HTML מבולגן ולא תקני, ערבוביה של תגיות HTML שכוללות תוכן, עיצוב ועימוד.
בקיצור, לא משהו שכיף במיוחד לחפוש בתוכו אחרי מידע.
הגישה הנאווית לבעיות כאלו היא שימוש בביטוי רגולרי, אבל זה לא יעבוד טוב בכל המקרים (מה קורה למשל אם יש HTML בתוך התאור של הטורנט?).
בחרתי ללכת לגישה טיפה יותר חזקה, והיא פירוק מלא של הHTML למבנה נתונים בזכרון, וניתוח של אותו מבנה.
ספרית ג'אווה שמאפשרת parsing כזה לHTML היא htmlparser הוותיקה.
אבל גם אם htmlparser מחזירה לנו עץ אובייקטים נוח, איך מוציאים ממנו את מה שמעניין? הוא ענק וסבוך ויותר מכל מסובך.
למזלי מצאתי בונה פילטרים ויזואלי עם htmlparser. אפשר להריץ אותו עם Java web start:
[code]
javaws http://htmlparser.sourceforge.net/samples/filterbuilder.jnlp
[/code]
או פשוט להריץ את הקוד ישירות (org.htmlparser.parserapplications.filterbuilder.FilterBuilder). עורך הפילטרים מאפשר ליצור פילטרים מורכבים בהדרגתיות תוך בדיקה מתמדת של התוצאה על דף הHTML שאתם רוצים לבדוק.
אזהרה: הוא לא הכי ידידותי בעולם, לוקח זמן להתרגל אליו – אבל הוא עובד.
לדוגמא, נניח שאנחנו רוצים לחלץ את רשימת השחקנים מהסרט ביוולף בIMDB.
קודם נכניס בשורה התחתונה את הURL, אחר כך נלחץ על fetch page, ואז נקבל את הHTML כעץ בחלק הימני.
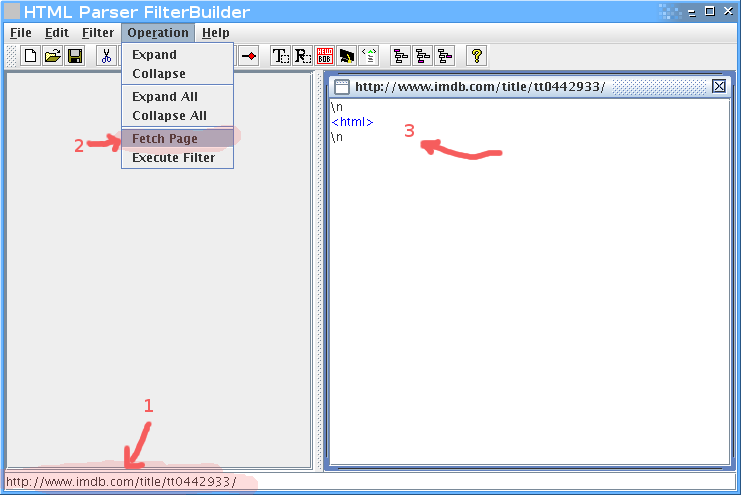
ברגע שיש לנו את הHTML, נתחיל לפלטר. חיפוש קצר אחרי שם של אחד השחקנים (Musician #2) מצא את הטבלא, ולמרבה הנוחות אפשר לראות שclass הCSS שלה הוא cast. זה מצויין, כי זה יאפשר לנו לדוג את הטבלא בקלות:
נוסיף פילטר של תכונות (attributes), נכניס בו את התכונה class עם הערך cast.
קליק ימני על הפילטר, execute filter, ונקבל חלון קטן בצד ימין עם התוצאות.
בינגו, יש לנו את הטבלה.
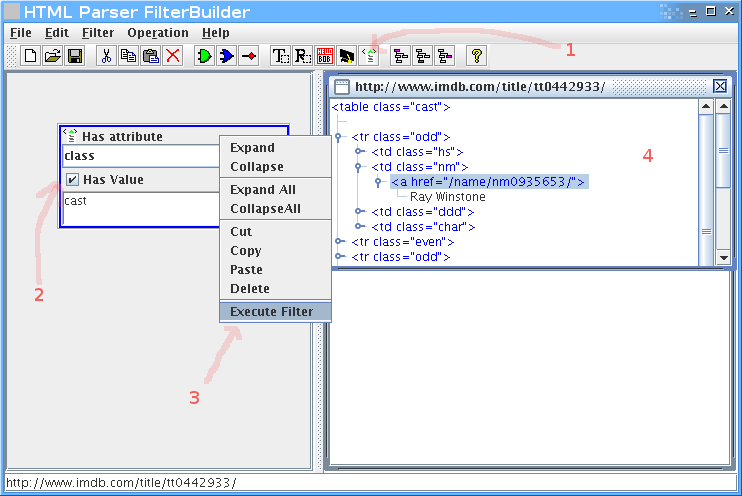
אבל אנחנו רוצים רק את רשימת השחקנים, אז צריך לעדן את הפילטר.
נוסיף שאנחנו רוצים רק טגים בשם TR, שיש להם הורה שהוא טבלא עם תכונה של class שערכו cast:
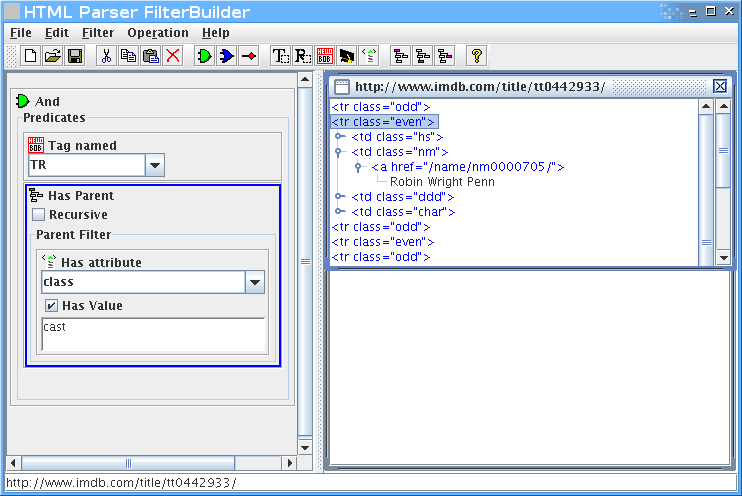
אפשר להמשיך, אבל הרעיון – אני מקווה – ברור.
ברגע שאנחנו מרוצים מהפילטר שיצרנו, אפשר לשמור אותו.
זה מה שיוצא (גרסא מקוצרת):
[code lang="java"]
// Generated by FilterBuilder. http://htmlparser.org
// [aced0005737200206f…….17374]
import org.htmlparser.*;
import org.htmlparser.filters.*;
import org.htmlparser.beans.*;
import org.htmlparser.util.*;
public class imdb
{
public static void main (String args[])
{
TagNameFilter filter0 = new TagNameFilter ();
filter0.setName ("TR");
HasAttributeFilter filter1 = new HasAttributeFilter ();
filter1.setAttributeName ("class");
filter1.setAttributeValue ("cast");
HasParentFilter filter2 = new HasParentFilter ();
filter2.setRecursive (false);
filter2.setParentFilter (filter1);
NodeFilter[] array0 = new NodeFilter[2];
array0[0] = filter0;
array0[1] = filter2;
AndFilter filter3 = new AndFilter ();
filter3.setPredicates (array0);
NodeFilter[] array1 = new NodeFilter[1];
array1[0] = filter3;
FilterBean bean = new FilterBean ();
bean.setFilters (array1);
if (0 != args.length)
{
bean.setURL (args[0]);
System.out.println (bean.getNodes ().toHtml ());
}
else
System.out.println ("Usage: java -classpath .:htmlparser.jar:htmllexer.jar imdb
}
}
[/code]
בראש הקובץ יש קידוד של הפילטר, מה שמאפשר לנו לטעון את הקובץ ולהמשיך לעבוד עליו מאותה נקודה.
כדי לקמפל את זה צריך כמובן את htmlfilter.jar בclasspath.
טוב, אז נניח שכתבנו פילטר מתאים, וגיבינו אותו בקצת קוד שמוציא את הנתונים לרשימה נוחה.
איך הופכים את זה לRSS?
בקלות, בעזרת ספרית ג'אווה בשם Rome.
השימוש ברומא פשוט מאוד, הנה דוגמא:
[code lang="java"]
public String getListRSS() throws FeedException
{
SyndFeed feed = new SyndFeedImpl();
feed.setFeedType("rss_2.0");
feed.setTitle("My RSS!");
feed.setLink("http://firefang.net/blog/768");
feed.setDescription("A feed for you!");
List entries = new ArrayList();
feed.setEntries(entries);
Vector v = new Vector();
v.add("item1");
v.add("item2");
v.add("item3");
for (int i = 0; i < v.size(); i++)
{
SyndEntry entry = new SyndEntryImpl();
entry.setTitle((String) v.elementAt(i));
entry.setLink("http:://imdb.com/");
entries.add(entry);
}
SyndFeedOutput output = new SyndFeedOutput();
return output.outputString(feed);
}
[/code]
שמפיקה את הRSS הזה:
[code lang="xml"]
[/code]
אז עכשיו שאנחנו יודעים לקחת דף HTML ולהוציא ממנו טקסט של RSS, נשאר רק לאפשר לקורא RSS רגילים לגשת אליו.
הדרך הטבעית תהיה להריץ שרת ווב קטן, שיגיש את קובץ הRSS למי שמבקש.
בחרתי להשתמש בJetty, שהוא שרת ווב קטן וגמיש בג'אווה, שמאפשר גם שילוב פשוט וקל בתוך אפליקציות אחרות.
לא להבהל מגודל ההורדה שלו, כדי להשתמש בו בתוך האפליקציה שלכם מספיק לקחת שלושה Jarים בגודל כולל של כ700K.
ככה משלבים את Jetty בתוך הישום שלכם, שימו לב כמה שזה פשוט.
[code lang="java"]
Handler handler=new AbstractHandler()
{
public void handle(String target, HttpServletRequest request, HttpServletResponse response, int dispatch)
throws IOException, ServletException
{
response.setContentType("text/html");
response.setStatus(HttpServletResponse.SC_OK);
response.getWriter().println("
Hello
");
((Request)request).setHandled(true);
}
}
Server server = new Server(8080);
server.setHandler(handler);
server.start();
[/code]
כדי לגשת אליו, נפתח את הדפדפן על http://localhost:8080 במקרה שלנו.
עכשיו רק נשאר לקשור את החוטים ביחד.
פתחתי בלוג קטן לפרוייקט, וחיש מהר החשבון שלי בTorrentLeech הושעה. כשביררתי מה הסיפור נאמר לי שהם חוששים שאני אגנוב למשתמשים סיסמאות.
הצעתי להם לבדוק את הקוד, ושעד אז אני אוריד את הלינק, וכך עשיתי, והחשבון שלי שוחזר.
בינתיים הם עדיין לא חזרו אלי, והסבלנות קצת פקעה.
מי שרוצה להוריד את הקוד יכול להוריד אותו מפה עם לקוח Subversion.
מי שרוצה להוריד את הבינארי מוזמן להוריד אותו מפה.
יש הוראות שימוש בתוך קובץ הREADME.
tl2rss משוחרר תחת רשיון GPL-3.0.
Sansa e280 וRockbox
כמו שאמרתי, קניתי נגן MP3 נייד, Sansa e280 עם 8 ג'יגה זכרון פלאש ותמיכה ברדיו.
התקנתי עליו את הנגן פתוח הקוד, Rockbox, ואני מרוצה.
רוקבוקס תומך בכל מה שאני צריך מבחינת שמישות, וגם בכמה דברים שאני לא ממש צריך, כמו משחק דום :).
יש לו סייר קבצים שמאפשר לעיין בקבצים בקלות, למחוק, להזיז וליצר רשימות ניגון.
בנוסף, הוא מגיע עם די הרבה פלאינים, תוכנות פשוטות (מטרונום למשל, שמאפשר לשמור על קצב הליכה קבוע) וערכות נושא.
במבט ראשון רוקבוקס נראה די מכוער, במיוחד אחרי שרואים את התוכנה המקורית שמגיעה עם הנגן, אבל אחרי שמשחקים קצת עם ערכות הנושא הוא נראה הרבה יותר טוב.
מה שבטוח זה שהוא נותן הרבה יותר פונקציונליות, ומאפשר – למי שבאמת רוצה – לשנות ולהרחיב את הנגן שלו. ההגבלה היחידה היא הדמיון.
מומלץ לגבות את הסנסה לפני שמתקינים עליו את רוקבוקס, אתם לא רוצים להתקע עם משקולת נייר יקרה ולא כבדה מספיק.
לפני שמחברים את הסנסה למחשב צריך לשנות את זיהוי הUSB שלו לMass storage class, או MSC. זה יאפשר למחשב לזהות אותו ככונן כמו כל כונן קשיח.
ללינוקסאים, כדי לגבת את כל הSansa, בהנחה שהוא הופיע בשם /dev/sdb
השתמשו בפקודה:
[code]
dd if=/dev/sdb of=~/sansa.full.img
gzip ~/sansa.full.img
[/code]
שתיצור עותק בינארי של כל הכונן (זה 8 ג'יגה, אז זה יקח זמן).
אפשר לגבות רק את המחיצה השניה (sdb2), שמכילה את התוכנה של הנגן, אבל אני חושב שליתר ביטחון עדיף לגבות את הכל.
בהנחה שהסנסה שלכם ריק, הgzip יתפוס כ100 מגה-בייט.
משתמשי חלונות מוזמנים לחפש פתרון בעצמם (רצוי כזה שלא דורש הקלדת פקודות קצרות אך מוזרות).

פייתון וPydev
כבר הרבה זמן פייתון נמצאת בtodo list שלי, ונראה לי שאני אתחיל ללמוד את השפה.
מצאתי את diveintopython, שמכיל ספר שנועד למפתחים מנוסים שרוצים ללמוד פייתון.
בינתיים נראה נחמד.
התקנתי את pydev, תוסף Eclipse שמאפשר פיתוח פייתון בסביבת Eclipse.
ההתקנה, כמו בדרך כלל – היא דרך אתר עדכון אוטומטי.
הסביבה כוללת Debug, השלמה אוטומטית, Refactoring ועוד הרבה דברים טיפוסיים לEclipse. בנוסף, יש לה אינטגרציה לMylyn – לשעבר Mylar.
(עוד על Mylyn בפוסט הזה).

(לחצו לעוד תמונות)
JavaMonkey engine
JavaMonkey הוא מנוע משחקים מרשים ופתוח קוד שכתוב בג'אווה.
המנוע מאפשר כתיבת משחקים תלת מימדיים בקלות, כולל תמיכה בOpenGL (בעזרת ספרייתLWJGL ) שמאפשרת גישה ליכולות של כרטיס המסך מג'אווה.
פרוייקט צדדי בשם jME Physics מאפשר התממשקות קלה למנוע הפיזיקה Open Dynamics Engine.
הגרסא האחרונה כוללת תמיכה באפלטים, מה שאומר שלא רחוק היום שנראה משחקי ג'אווה תלת מימדים בדפדפן.
IP2C תכנון, מימוש ושיקולי יעילות
IP2C היא ספריה קטנה למציאת קוד המדינה אליה שייכת כתובת IP.
הספרייה מכילה נכון לכרגע מימוש בPHP ובג'אווה, וכוללת ומבוססת על המרת הנתונים לקובץ בינארי קומפקטי שמתוכנן לחיפוש מהיר.
בסיס נתונים של נתוני IP למדינה זה דבר די גדול, בסיס הנתונים החינמי של WHI שמגיע כקובץ CSV מכיל כ77000 טוחי כתובות (הטווח מכתובת X לכתובת Y שייך למדינה C) ובסיסי נתונים אחרים הם הרבה יותר גדולים.
כשרוצים לחפש בדבר כזה יש כמה אפשרויות:
1. העלאת הנתונים לטבלא לבסיס הנתונים ושימוש בבסיס הנתונים לחיפוש.
2. המרה של קובץ הCSV לקובץ בינארי חסכוני ואז חיפוש בקובץ. על הדרך הזו המשך הפוסט מדבר.
הגישה הראשונה בעייתית כי היא דורשת גישת מנהל לבסיס הנתונים כדי לבצע יבוא מהיר, או דורשת עדכון בלולאה – מה שלוקח דקות ארוכות.
הגישה השניה עדיפה כי הנתונים תופסים פחות מקום וקל יותר לעדכן אותם, בנוסף אין תלות בבסיס נתונים.
שורה בקובץ הCSV המקורי מכילה תחילת טווח, סוף טווח, ומידע לגבי הטווח – כמו קוד ISO של המדינה והשם שלה. שורה לדוגמא:
"201620312","201674095","US","USA","UNITED STATES"
נניח שאנחנו שומרים את הנתונים האלו לקובץ בצורה הזו:
לכל מדינה:
4 בתים: תחילת טווח.
4 בתים: סוף טווח.
2 בתים קודISO
X בתים שם מדינה.
יש פה בעיה, כי שם המדינה הוא לא באורך ידוע, מה שלא מאפשר גישה ישירה לנתונים (כדי להגיע לשורה X צריך לסרוק את כל השורות שלפניה).
פתרון חלופי הוא לחלק את הקובץ לשני תחומים כדלקמן:
חלק ראשון בקובץ, לכל מדינה:
4 בתים: תחילת טווח.
4 בתים: סוף טווח.
2 בתים קודISO
4 בתים ההיסט של שם המדינה בתוך הקובץ
חלק שני בקובץ, לכל מדינה:
X בתים: שם המדינה.
זה כבר יותר טוב, עכשיו אפשר לחפש חיפוש בינארי בחלק הראשון, ולמצוא את שם המדינה לפי ההיסט שמצאנו ברשומה בחלק הראשון.
נניח שאלו הנתונים שלנו:
1. 1 עד 10 : ישראל
2. 10 עד 20: הודו
3. 20 עד 22: סין
4. 25 עד 30: ארצות הברית
אפשר לשים לב שלמעט המעבר מסין לארצות הברית טווח n תמיד מתחיל איפה שטווח n-1 נגמר.
ככה זה גם במציאות, כמעט תמיד אין חורים בין הטווחים.
זה מאפשר לנו ליעל את צורת השמירה: פשוט נשמור רק את תחילת הטווח של כל שורה, ונשתמש בתחילת הטווח של השורה הבאה בתור סמן לסוף הטווח.
אבל אני שומע את הצעקות: אבל מה עם סין? היא תקבל עוד שלוש כתובות!
הפתרון הפשוט למדי הוא להוסיף שורת סרק אחרי סין, שסוגרת את הטווח שלה:
1. 1 : ישראל
2. 10: הודו
3. 20 : סין
4. 22: אף אחד
4. 25 : ארצות הברית
…
חסכנו בממוצע 4 בתים מתוך 14, שזה כשלושים אחוז מנפח הנתונים, בלי לאבד שום דבר.
כמובן שהאלגוריתם של החיפוש יצטרך להתחשב בשורות ששייכות ל"אף אחד", מה שיסבך אותו, אבל זה שווה את המחיר.
אופטימיציה נוספת שמתבקשת היא לשמור את שם המדינה ואת הנתונים הנילוים (קוד מדינה וכו') פעם אחת בלבד לכל מדינה.
מה שיוביל לחסכון רציני נוסף בנפח הנתונים.
למעשה הקובץ שIP2C מייצרת אפילו יותר חסכוני מזה, החלק הראשון של הקובץ מכיל שורות בצורת:
IP התחלה: 4 בתים.
קוד מדינה: 2 בתים.
החלק השני של הקובץ מכיל עוד טבלה מאפשרת לגשת לשאר הנתונים (שם מדינה וכו'), אבל מחיב הפעלת חיפוש בינארי שני (במילים אחרות, המרתי את הנפח הדרוש להיסט בזמן מעט גבוה יותר לחיפוש).
בממוצע, כל טווח מהקובץ המקורי תופס כ7 בתים בקובץ, מאד חסכוני לכל הדעות.
גישה לנתונים
עכשיו שסגרנו את מבנה הקובץ (פחות או יותר), הגיע הזמן לדבר על דרך הגישה אל הנתונים.
יש כמה דרכים, שלא כולן ישימות בכל שפה:
טעינת הקובץ לזכרון
הגישה הטבעית שכמעט כולם יבחרו תהיה להעלות את כל הקובץ לזכרון (סך הכל חצי מגה במקרה שלי) ולחפש בתוכו.
יש שתי חסרונות לגישה הזו: הראשונה היא צריכת הזכרון שפרופורציונית לגודל הקובץ, והשניה היא שהזמן לחיפוש הראשון הוא גדול כי משלמים גם על טעינת הקובץ.
מצד שני החיפוש עצמו מהיר מאוד, הכי מהיר למעשה מכל הגישות האחרות.
הגישה הזו לא אופטימלית לPHP בדרך כלל, כי בכל בקשה נצטרך לטעון את הקובץ מחדש.
הגישה הזו ממומשת כרגע במימוש בJava בלבד.
חיפוש ישירות על הקובץ
הטכניקה הזו היתה הרבה יותר נפוצה בעבר, כש640K היו צריכים להספיק לכולם.
במקום לטעון את הקובץ כולו לזכרון, מבצעים את החיפוש הבינארי ישירות על הקובץ.
החסרון הוא שזה איטי משמעותית יותר מחיפוש בזכרון, והיתרונות הם שצריכת הזכרון מינימלית ושהמחיר של החיפוש הראשון זול בדיוק כמו של אלו שאחריו.
הגישה הזו מתאימה מאוד לPHP, במיוחד אם צריך לבצע מספר קטן של חיפושים בכל בקשה.
מימוש: Java וPHP.
קובץ ממופה זכרון
קובץ ממופה זכרון (Memory mapped file) לוקח את הטוב משני העולמות. מצד אחד לא טוענים את כל הקובץ לזכרון, מצד שני המהירות קרובה למהירות חיפוש בזכרון.
PHP לא תומך בזה, אבל ג'אווה כן – וקיבלתי תוצאות יפות למדי עם זה.
היתרונות הם שכמו בחיפוש ישירות על הקובץ, לא טוענים את כל הקובץ לזכרון בהתחלה ולכן החיפוש הראשון יהיה מהיר בערך כמו החיפוש הראשון בחיפוש ישיר על הקובץ, אבל החיפושים הבאים יתקרבו למהירות חיפוש בזכרון. החיסרון העיקרי הוא שלא כל הפלטפורמות תומכות בזה.
מימוש: Java בלבד.
זכרון משותף
זכרון משותף (Shared memory) היא עוד גישה. הפעם הקובץ נטען פעם אחת ויחידה לזכרון, ונשאר שם. הגישה הזו מנטרלת את הבעיה המרכזית של PHP עם הגישה של טעינת הקובץ לזכרון (שצריך לטעון אותו כל פעם מחדש), אבל עדיין סובלת מהבעיה של צריכת זכרון גבוהה (למעשה הבעיה מחריפה גם הזכרון יהיה בשימוש גם אם אף אחד לא רוצה לבצע חיפוש במשך שבוע).
גם PHP וגם Java תומכים בזכרון משותף, אבל לא בדקתי את הביצועים של מימוש כזה.
מימוש: לא ממומש.
IP2C משוחררת ברשיון GPL2, והיא קלה מאוד לשימוש.
FireStats 1.3.0
בשעה טובה, שחררתי את FireStats 1.3.0-beta.
בין השינויים המשמעותיים בגרסא:
- תמיכה בדחיסת נתונים ישנים שמשפרת ביצועים ומקטינה את נפח הנתונים בבסיס הנתונים.
- הצגת מילות חיפוש ממנועי חיפוש
- אפשרות לקבוע ערכי בסיס לדפים שנצפו ומבקרים
- מסך דיאגנוזה לזיהוי בעיות בצורה אוטומטית
ועוד.
יש צילומי מסך והסברים על הגרסא החדשה פה
אזהרה:
זו גרסאת בטא, והיא מומלצת לבדיקות בלבד.
הPHP 4.4 מת, יחי הPHP 5.2!
צוות הפיתוח של PHP הכריז היום על סוף החיים של PHP4:
בסוף 2007 תיפסק התמיכה בPHP4, ויפסיקו לצאת גרסאות חדשות של PHP 4.4.
עד 08/08/08, בשעה 8:88 בבוקר עדיין יצאו עדכוני אבטחה קריטיים, ואחר כך גם זה לא.
לדעתי הקמפיין של gophp5 העיר את צוות הפיתוח, ובעקבות הקמפיין וההכרזה אנחנו עומדים לראות פרוייקטים רבים יותר ויותר עוברים לPHP5.
Go PHP5
PHP4 יצא בשנת 2000, ועשה עבודה טובה. לפני שלוש שנים יצא PHP5, אבל האימוץ שלו מתקדם באיטיות.
הסיבה המרכזית היא שספקי שרותי האירוח (Hosting) לא משדרגים כי אין עליהם לחץ מהמשתמשים, ומפתחי התוכנות ממשיכים לתמוך בPHP4 כי ספקי שרותי האירוח לא משדרגים.
ביצה ותרנגולת.
הבעיה היא שPHP5 כוללת הרבה שיפורים – למשל תמיכה יותר טובה בתכנות מונחה עצמים, שיפורי אבטחה רבים ותכונות שימושיות כמו תמיכה בXML ובJSON.
מפתחים נאלצים לא להשתמש ביכולות החדשות, מה שגורם לקוד להיות יותר מורכב, או אפילו לפחות תכונות בישומים.
קהילת מפתחי הPHP, כולל מפתחי פרוייקטים כמו דרופל וPhpMyAdmin החליטו לנסות לשבור את המעגל.
החל מ5.2.2008 תכונות חדשות שישוחררו בפרוייקטים האלו ובאחרים ידרשו PHP 5.2 כדרישת סף.
לצורך העניין הוקם אתר GoPHP5, שירכז שמות פרוייקטים שיפסיקו לתמוך בPHP4 וושמות ספקי אירוח שיתמכו בPHP5 כברירת מחדל.
אני תומך ברעיון, אבל רק פרוייקטים שמטבעם מותקנים על ידי מנהלי המערכות יכולים לעשות צעד כזה.
אני מקווה שהם יצברו מספיק מומנטום כדי לשנות את המצב.

אולו
ohloh סורק קוד מקור של פרוייקטים פתוחי קוד, ומציג נתונים מעניינים כמו מספר שורות הקוד, והערכה של מספר שנות האדם שנדרשות כדי לפתח משהו דומה.
בנוסף הוא מאפשר למפתחים ליצור מעיין פרופיל קוד פתוח, שיכיל מידע מרוכז על הפרוייקטים להם הם תרמו קוד.
כמובן שכדי לעשות את זה, המפתחים צריכים להוסיף את הפרוייקטים להם הם תרמו לאולו, מה שהופך את העסק לוויראלי מאוד.
מאחורי הקלעים, אולו מוריד את ההיסטוריה של הקוד ממאגר הקוד (svn,cvs או git), ומנתח את הקוד.
אולו גם חושף בעיות רישוי אפשריות שיתכן שהמפתחים עצמם לא מודעים להן.
למשל, הידעתם שפיירפוקס כתוב ברובו בC++, שהפיתוח שלו מאוד פעיל, שיש בו כמעט 1.8 מליון שורות קוד ושהושקעו בו כ504 שנות אדם?
הידעתם שוורדפרס כתוב ברובו בPHP, שקצב הפיתוח שלו עולה משנה לשנה, שיש בו כ62 אלף שורות קוד ושהשקעו בו כ15 שנות אדם?
אולו מאפשר הוספה של תגיות חביבות שמקשרות לפרוייקט או לפרופיל שלכם:
![]()