לפני כמה שבועות הפיד RSS של TorrentLeech (להלן TL), ספק הסדרות העיקרי שלי, התחיל להחזיר 404 (דף לא נמצא).
אין פה שום דבר חדש, הפיד הזה אף פעם לא היה יציב במיוחד, לכן חיכיתי בסבלנות כשבוע, ואז התלוננתי בערוץ הIRC שהלינק של הפיד לא עובד.
גורם "רשמי" מסר לי שהפיד לא יחזור כי השתמשו בו לרעה.
ניסיתי לברר את פשר השימוש הפוחז, ואפילו הצעתי את עזרתי במציאת פיתרון, אך לשוא:
הילדון זב החוטם מסר שלא משנה מה אני אגיד או אעשה, הפיד לא חוזר.
הסברתי לו בדרכי נועם שאם המידע זמין באתר, אין שום הבדל כי אפשר להפוך אותו לפיד, אבל זה לא עזר.
אז החלטתי לעשות בדיוק את זה, וכך נולדה תוכנה חדשה – TorrentLeech2RSS.
בגדול, הרעיון הוא כזה:
שרת מקומי דוגם את TL, נניח פעם בחצי שעה.
השרת נכנס לTL, מזדהה עם שם המשתמש והסיסמא של המשתמש בTL, מוריד את דף הHTML שמכיל את רשימת הטורנטים בכל אחת מהקטגוריות הנבחרות, מפענח את הדף, ומחלץ ממנו את השם, הלינק, המזהה והתאריך של כל טורנט, ושומר אותם בזכרון.
במקום להשתמש בכתובת הRSS של TL (שאינה עימנו עוד), המשתמש מכניס כתובת של TorrentLeech2RSS, שמכין דף RSS ומחזיר אותו למבקש.
TorrentLeech2RSS גם משכתב את הלינקים בתוך הRSS שיעברו דרכו, כדי שיוכל להוסיף פרטי הזדהות שיעברו לשרת של TL ברגע שהמשתמש מנסה להוריד טורנט (אחרת הTracker של TL לא משתף פעולה עם המשתמש).
בחרתי לכתוב את tl2rss בשפת ג'אווה.
הצעד הראשון, וכנראה הכי קשה בתהליך, הוא להכנס תכנותית לאתר, התהליך מורכב יחסית וכולל כמה שלבים.
כדי להבין מה אני אמור לשלוח ומתי, השתמשתי בWireShark, וניטרתי את התעבורה שנוצרת כשאני מבצע לוגין בעזרת הדפדפן.
שימו לב במיוחד לאפשרת של Follow TCP Stream, שמציגה שיחת HTTP שלמה בצורה ברורה.
ברגע שהקוד הצליח להזדהות מול השרת, לבקש דף שמתאים לקטגוריה רלוונטית זה קל. אבל מה עושים עם הדף?
הדפים של TorrentLeech הם דוגמא לאיך נראה קוד HTML מבולגן ולא תקני, ערבוביה של תגיות HTML שכוללות תוכן, עיצוב ועימוד.
בקיצור, לא משהו שכיף במיוחד לחפוש בתוכו אחרי מידע.
הגישה הנאווית לבעיות כאלו היא שימוש בביטוי רגולרי, אבל זה לא יעבוד טוב בכל המקרים (מה קורה למשל אם יש HTML בתוך התאור של הטורנט?).
בחרתי ללכת לגישה טיפה יותר חזקה, והיא פירוק מלא של הHTML למבנה נתונים בזכרון, וניתוח של אותו מבנה.
ספרית ג'אווה שמאפשרת parsing כזה לHTML היא htmlparser הוותיקה.
אבל גם אם htmlparser מחזירה לנו עץ אובייקטים נוח, איך מוציאים ממנו את מה שמעניין? הוא ענק וסבוך ויותר מכל מסובך.
למזלי מצאתי בונה פילטרים ויזואלי עם htmlparser. אפשר להריץ אותו עם Java web start:
[code]
javaws http://htmlparser.sourceforge.net/samples/filterbuilder.jnlp
[/code]
או פשוט להריץ את הקוד ישירות (org.htmlparser.parserapplications.filterbuilder.FilterBuilder). עורך הפילטרים מאפשר ליצור פילטרים מורכבים בהדרגתיות תוך בדיקה מתמדת של התוצאה על דף הHTML שאתם רוצים לבדוק.
אזהרה: הוא לא הכי ידידותי בעולם, לוקח זמן להתרגל אליו – אבל הוא עובד.
לדוגמא, נניח שאנחנו רוצים לחלץ את רשימת השחקנים מהסרט ביוולף בIMDB.
קודם נכניס בשורה התחתונה את הURL, אחר כך נלחץ על fetch page, ואז נקבל את הHTML כעץ בחלק הימני.
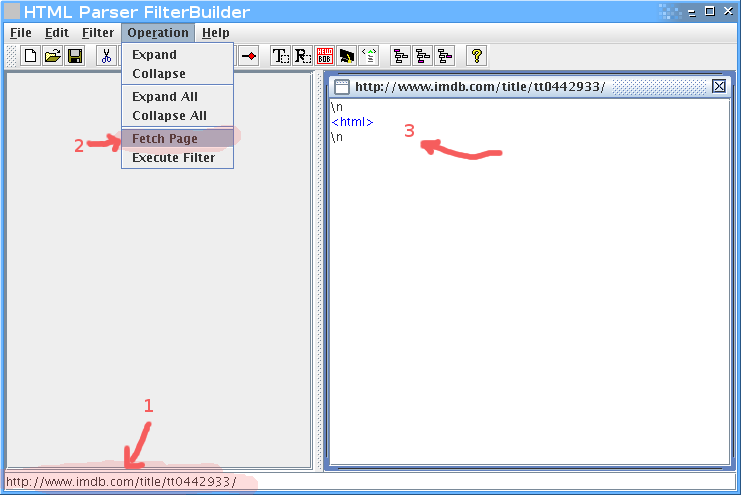
ברגע שיש לנו את הHTML, נתחיל לפלטר. חיפוש קצר אחרי שם של אחד השחקנים (Musician #2) מצא את הטבלא, ולמרבה הנוחות אפשר לראות שclass הCSS שלה הוא cast. זה מצויין, כי זה יאפשר לנו לדוג את הטבלא בקלות:
נוסיף פילטר של תכונות (attributes), נכניס בו את התכונה class עם הערך cast.
קליק ימני על הפילטר, execute filter, ונקבל חלון קטן בצד ימין עם התוצאות.
בינגו, יש לנו את הטבלה.
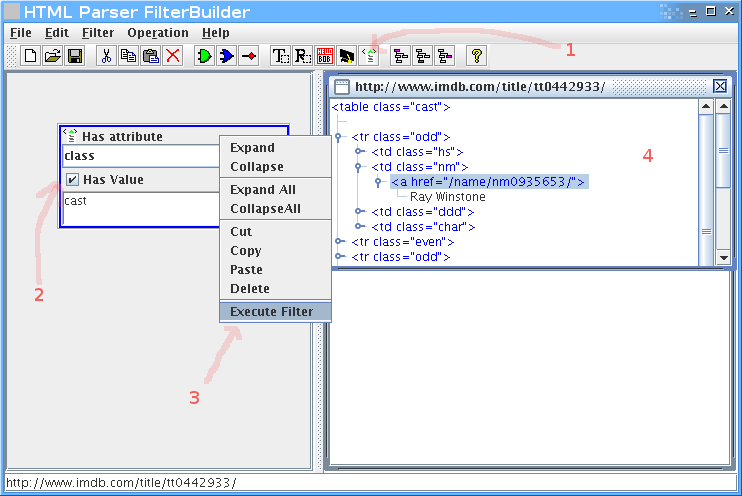
אבל אנחנו רוצים רק את רשימת השחקנים, אז צריך לעדן את הפילטר.
נוסיף שאנחנו רוצים רק טגים בשם TR, שיש להם הורה שהוא טבלא עם תכונה של class שערכו cast:
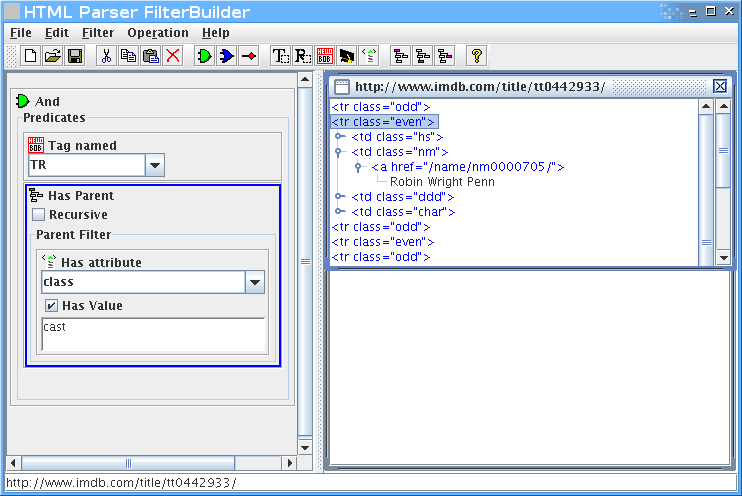
אפשר להמשיך, אבל הרעיון – אני מקווה – ברור.
ברגע שאנחנו מרוצים מהפילטר שיצרנו, אפשר לשמור אותו.
זה מה שיוצא (גרסא מקוצרת):
[code lang="java"]
// Generated by FilterBuilder. http://htmlparser.org
// [aced0005737200206f…….17374]
import org.htmlparser.*;
import org.htmlparser.filters.*;
import org.htmlparser.beans.*;
import org.htmlparser.util.*;
public class imdb
{
public static void main (String args[])
{
TagNameFilter filter0 = new TagNameFilter ();
filter0.setName ("TR");
HasAttributeFilter filter1 = new HasAttributeFilter ();
filter1.setAttributeName ("class");
filter1.setAttributeValue ("cast");
HasParentFilter filter2 = new HasParentFilter ();
filter2.setRecursive (false);
filter2.setParentFilter (filter1);
NodeFilter[] array0 = new NodeFilter[2];
array0[0] = filter0;
array0[1] = filter2;
AndFilter filter3 = new AndFilter ();
filter3.setPredicates (array0);
NodeFilter[] array1 = new NodeFilter[1];
array1[0] = filter3;
FilterBean bean = new FilterBean ();
bean.setFilters (array1);
if (0 != args.length)
{
bean.setURL (args[0]);
System.out.println (bean.getNodes ().toHtml ());
}
else
System.out.println ("Usage: java -classpath .:htmlparser.jar:htmllexer.jar imdb
}
}
[/code]
בראש הקובץ יש קידוד של הפילטר, מה שמאפשר לנו לטעון את הקובץ ולהמשיך לעבוד עליו מאותה נקודה.
כדי לקמפל את זה צריך כמובן את htmlfilter.jar בclasspath.
טוב, אז נניח שכתבנו פילטר מתאים, וגיבינו אותו בקצת קוד שמוציא את הנתונים לרשימה נוחה.
איך הופכים את זה לRSS?
בקלות, בעזרת ספרית ג'אווה בשם Rome.
השימוש ברומא פשוט מאוד, הנה דוגמא:
[code lang="java"]
public String getListRSS() throws FeedException
{
SyndFeed feed = new SyndFeedImpl();
feed.setFeedType("rss_2.0");
feed.setTitle("My RSS!");
feed.setLink("http://firefang.net/blog/768");
feed.setDescription("A feed for you!");
List entries = new ArrayList();
feed.setEntries(entries);
Vector v = new Vector();
v.add("item1");
v.add("item2");
v.add("item3");
for (int i = 0; i < v.size(); i++)
{
SyndEntry entry = new SyndEntryImpl();
entry.setTitle((String) v.elementAt(i));
entry.setLink("http:://imdb.com/");
entries.add(entry);
}
SyndFeedOutput output = new SyndFeedOutput();
return output.outputString(feed);
}
[/code]
שמפיקה את הRSS הזה:
[code lang="xml"]
[/code]
אז עכשיו שאנחנו יודעים לקחת דף HTML ולהוציא ממנו טקסט של RSS, נשאר רק לאפשר לקורא RSS רגילים לגשת אליו.
הדרך הטבעית תהיה להריץ שרת ווב קטן, שיגיש את קובץ הRSS למי שמבקש.
בחרתי להשתמש בJetty, שהוא שרת ווב קטן וגמיש בג'אווה, שמאפשר גם שילוב פשוט וקל בתוך אפליקציות אחרות.
לא להבהל מגודל ההורדה שלו, כדי להשתמש בו בתוך האפליקציה שלכם מספיק לקחת שלושה Jarים בגודל כולל של כ700K.
ככה משלבים את Jetty בתוך הישום שלכם, שימו לב כמה שזה פשוט.
[code lang="java"]
Handler handler=new AbstractHandler()
{
public void handle(String target, HttpServletRequest request, HttpServletResponse response, int dispatch)
throws IOException, ServletException
{
response.setContentType("text/html");
response.setStatus(HttpServletResponse.SC_OK);
response.getWriter().println("
Hello
");
((Request)request).setHandled(true);
}
}
Server server = new Server(8080);
server.setHandler(handler);
server.start();
[/code]
כדי לגשת אליו, נפתח את הדפדפן על http://localhost:8080 במקרה שלנו.
עכשיו רק נשאר לקשור את החוטים ביחד.
פתחתי בלוג קטן לפרוייקט, וחיש מהר החשבון שלי בTorrentLeech הושעה. כשביררתי מה הסיפור נאמר לי שהם חוששים שאני אגנוב למשתמשים סיסמאות.
הצעתי להם לבדוק את הקוד, ושעד אז אני אוריד את הלינק, וכך עשיתי, והחשבון שלי שוחזר.
בינתיים הם עדיין לא חזרו אלי, והסבלנות קצת פקעה.
מי שרוצה להוריד את הקוד יכול להוריד אותו מפה עם לקוח Subversion.
מי שרוצה להוריד את הבינארי מוזמן להוריד אותו מפה.
יש הוראות שימוש בתוך קובץ הREADME.
tl2rss משוחרר תחת רשיון GPL-3.0.
ועל כך, כל הכבוד!
אני משוכנע שחיש מהר יבינו איזו טובה ענקית עשית להם.
מזכיר לי את ימי feeds2.be העליזים.
אני, אגב, העדפתי להשתמש בביטוי רגולרי, מתוך הנחה שהוא הרבה פחות פגיע לשינויים ב DOM.
חבל שעבדת כל כך קשה
היה לוקח לך 2 דקות עם Dapper
http://www.dapper.net
מורפי:
לא עשיתי להם טובה, מקסימום למשתמשים שלהם.
דור:
יש דברים שביטוי רגולרי פשוט לא יכול לתפוס (מתמטית).
עוזי:
אכן נחמד, לא הכרתי.
אבל לא הייתי משתמש בזה בכל מקרה משתי סיבות:
1. לא אוהב לתת את הסיסמאות שלי לכל מני אתרי צד גימל.
2. זה לא היה מאפשר לי להוריד טורנטים בצורה אוטומטית (ראה מה כתבתי על שכתוב של הלינקים אל הטורנטים). אומנם חלק מסורקי הרסס מסוגלים לקבל קוקיז לשליחה, אבל זה פחות יפה מהפתרון שלי שעובד בכל מקרה.
אתה צודק, כמובן, אבל בכל העובדה על האתר לא נתקלתי במקרה כזה
עמרי,
לא קראתי עדיין, את מה שקראתי עדיין לא הבנתי, אני לא משתמש באתר הזה ולא יודע מה היה קודם ומה אין עכשיו, וברור שאני לא מבין כרגע מה עשית.
אבל אתה גאון, זה בטוח!
וגם נתת לי חומר לקריאה ומספר כלים שאני לא מכיר. אני צריך לקרוא את מה שעשית ולהבין מה הולך שם. זה מעניין מאוד גם למי שלא מתכנת בג'אווה.
תודה!
אתה יודע איך קוראים לסקריפט של האתר TL?
איזה סקריפט?
אחלה עבודה.
עכשיו נשאר רק לשאול אם אתה יכול לשלוח לי הזמנה לאתר הזה? 🙂
תודה גיא.
למרבה הצער, ההזמנות שם מבוטלות נכון לפעם האחרונה שבדקתי.